9.6 継承/派生
この項では、今まで学習してきたクラスの概念に加えて継承という新しい概念を取り入れていきます。継承という概念によって既存のクラスの再利用性を高めたり、継承させたクラスに対して一定の強制力を持たせる事ができます。しかしむやみやたらに継承すれば、ただ複雑になるだけで利点を活かす事ができません。効果的に継承を使えるように、しっかりと本項目で学んでいきましょう。
9.6.1 継承の基本構文とアクセスレベル
まずは継承をどのように記述するのか見てしまいましょう。以下のコードを見てください。
struct X{
void f(){std::cout<<__func__<<std::endl;}
};
struct Y:public X{}; // クラスXを継承したクラスYを定義
継承を行うには、上記の通り、structもしくはclassでクラス名を宣言した後に:を記述し、その後アクセスレベルを付与し、継承するクラス名を付与します。継承を行ったクラスをインスタンス化して使って見ましょう。
#include<iostream>
struct X{
void f(){std::cout<<__func__<<std::endl;}
};
struct Y:public X{};
int main()
{
Y y;
y.f();
}
クラスYにはfという関数を定義していませんが、呼び出せています。継承によって、Xからfを引き継いでいるので、fを利用する事ができるのです。以下、用語の紹介まで上記の場合のクラスXを派生元クラス、クラスYを派生先クラスと呼称します。尚、派生先クラスの定義を記述する場合、その記述する位置から派生元クラスの定義が見えていなければなりません。つまり、派生先クラスの定義において、派生元クラスの前方宣言だけではプログラムとしては不適合となります。
struct X; // クラスの前方宣言
struct Y:public X{ // NG
// ...
};
ところで、継承した際に指定したアクセスレベルは、一体どのような効果を発揮するのでしょうか。
struct X{
int x=10;
};
struct Y:private X{}; // 継承時のアクセスレベルをprivateにしてみる
int main()
{
Y y;
y.x=20;
}
`
このコードはコンパイルに失敗します。エラー文では内容として派生元のクラスに対してprivateである事が示されています。つまり、継承時のアクセスレベルの設定は、継承先から継承元を見た時に、どのようなアクセスレベルとして捉えるかを設定するものであるかという事です。この場合、privateに設定しているため、継承先のクラスYからはXのメンバーが全てprivateアクセスレベルであると認識するのです。よってクラスYのインスタンスからは、Xの内部メンバにアクセスする事ができないのです。しかし、private継承を行なっても、以下のように、継承先の内部で、継承元のメンバにアクセスする事は可能です。
struct X{
int x=10;
};
struct Y:private X{
constexpr int get()const noexcept{return x;} // 継承先のメンバからはアクセス可
};
int main()
{
Y y;
y.get();
}
ところでアクセスレベルは、public、privateの他に、protectedというものがあります。protectedは、自身と、継承先にのみメンバを公開する事を意味するアクセスレベルです。
struct X{
int a; // 全てに公開
protected:
int b; // 自身と継承先に公開
private:
int c; // 自身にのみ公開
// X::a,X::b,X::cの全てにアクセスできる
};
struct Y:public X{
// X::a、X::bにアクセスできる
};
int main()
{
// X::aを操作できる
}
継承先に対するアクセスレベルにもprotectedを指定する事ができます。protectedを指定した場合、派生先からは派生元のpublic、protectedはprotectedに、privateはprivateアクセスレベルとして捉えます。
struct X{
int a;
protected:
int b;
private:
int c;
};
struct Y:protected X{
// X::a,X::bにアクセスできる
};
int main()
{
X x;
x.a; // Xのインスタンスからはaにアクセスできる
Y y;
y.a: // エラー!Yのインスタンスからはaはprotectedとして捉えられるためアクセスできない
}
尚、継承時にアクセスレベルを指定しない事もできます。
struct W{};
struct X:W{}; // public継承
class Y{};
struct Z:Y{}; // private継承
その場合、派生元がstructキーワードを用いてクラスを定義しているかclassキーワードを用いてクラスを定義しているかでその意味は異なります。派生元クラスがstructキーワードで宣言されたクラスであり、そのクラスに対してアクセスレベルを指定せずに継承した場合、public継承となり、派生元クラスがclassキーワードで宣言されたクラスであり、そのクラスに対してアクセスレベルを指定せずに継承した場合private継承となります。
ところで、継承したクラスのコンストラクタ、デストラクタはどのように動作するのでしょうか。継承元にデータメンバを保持していた場合、継承元のデータメンバも正しく生成、破棄される必要がありますから継承元のクラスのコンストラクタやデストラクタも動作しそうです。実際に確認してみましょう。
#include<iostream>
struct X{
explicit X(){std::cout<<__func__<<std::endl;}
~X(){std::cout<<__func__<<std::endl;}
};
struct Y:X{
explicit Y(){std::cout<<__func__<<std::endl;}
~Y(){std::cout<<__func__<<std::endl;}
};
int main()
{
Y();
}
実行結果は以下の通りです。
X
Y
~Y
~X
まず派生元のクラスのコンストラクタ、次に派生先のクラスのコンストラクタ、破棄時にはまず派生先のクラスのコンストラクタ、次に派生元のクラスのデストラクタが呼ばれます。このように、コンストラクタとデストラクタの呼び出し順序は生成と破棄で逆順になります。
最後に用語をまとめておきましょう。継承元となるクラスのことをスーパークラス(親クラス、基本クラスなど)と言い、継承を行うクラスをサブクラス(子クラス、派生クラスなど) といいます。
9.6.2 継承コンストラクタ
以下のコードを見てください。
#include<utility>
struct X{
explicit X()=default;
constexpr X(int x):a(std::move(x)){}
protected:
int a;
};
struct derived:X{
derived(int x)
{
a=std::move(x);
}
};
int main()
{
derived d=42;
}
クラスXはaというメンバをprotectedアクセスレベルで持っています。それを継承して利用するderivedクラスを後に定義していますが、ここでderivedのコンストラクタを見てください。derivedのコンストラクタでX内のメンバaを初期化したいところですが、上記のコードでは初期化ではなく、代入操作を行なっています。
ここで、
derived(int x):a(std::move(x))
{
// ...
}
とすれば初期化できるのではないかと思うかも知れませんがこのように記述する事はできません。何故ならばaはderivedクラスのメンバーではないからです。
では継承元のクラスのメンバーは初期化が行えないのでしょうか。勿論、そんな事はありません。継承元のコンストラクタを派生クラスから呼び出せば実現できます。
#include<utility>
struct X{
explicit X()=default;
constexpr X(int x):a(std::move(x)){}
protected:
int a;
};
struct derived:X{
derived(int x):X(std::move(x)){} // 継承元であるXのコンストラクタに引数xを受けわたす。
};
int main()
{
derived d=42;
}
この時、継承元のコンストラクタで継承元の内部にあるメンバについての初期化が行えるコンストラクタが定義されていない場合継承、元のメンバをその派生クラスから初期化する事はできません。例えば、継承元のクラスが以下のような実装であった場合、継承先から継承元のクラスXにおけるメンバ変数aの初期値を設定する事はできません。
// aに初期値を与える術がない
struct X{
explicit X()=default;
protected:
int a;
};
さて、上記の通り継承元のクラスのコンストラクタを明示的に呼び出す事で、継承元のコンストラクタに値を受け渡す事で継承元のメンバに初期値を与えていましたが、継承先へ初期値を受けわたすこの記述はとてもよく行うものであるので、以下のように初期値を受け渡して初期化させるコンストラクタを暗黙宣言させる事ができます。この機能を継承コンストラクタと言います。
#include<utility>
struct X{
explicit X()=default;
constexpr X(int x):a(std::move(x)){}
protected:
int a;
};
struct derived:X{
using X::X; // 継承コンストラクタ
// derived(),constexpr derived(int)が暗黙宣言される
};
int main()
{
derived d=42;
}
継承コンストラクタの機能によって暗黙宣言されるコンストラクタは上記コメントの通り、継承元クラスのコンストラクタがconstexprで宣言されている場合、継承先もまたconstexprで暗黙宣言されます。つまり、これら全ての機能を受けつぐ形で暗黙宣言されます。
また、継承元コンストラクタがdelete指定されており、それを継承コンストラクタの機能で暗黙宣言させた場合、それもまた同じく受け継ぐ形で、delete指定されて暗黙宣言されます。
因みに、このような文法を糖衣構文(Syntax sugar)と言ったりします。ある機能がなくとも実現は可能であるが、文法によるサポートで簡易的に記述できるような構文を、このように言います。
9.6.3 隠蔽
基底クラスにあるメンバ関数と同じ名前のメンバ関数を派生クラスで定義すると、 基底クラスのメンバ関数は隠されてしまいます。 これを、隠蔽と呼びます。
#include<iostream>
struct X{
void f(){std::cout<<"X::"<<__func__<<std::endl;}
};
struct derived:X{
void f(){std::cout<<"derived::"<<__func__<<std::endl;}
};
int main()
{
derived d;
d.f();
}
実行結果は以下の通りです。
derived::f
また、Derivedクラスのメンバ関数内から何のスコープ解決を行わずに呼び出した場合も、自分自身が持っている derived::fメンバ関数を呼び出します。
#include<iostream>
struct X{
void f(){std::cout<<"X::"<<__func__<<std::endl;}
};
struct derived:X{
void f(){std::cout<<"derived::"<<__func__<<std::endl;}
void g(){f();} // スコープ解決なしでfを呼び出し
};
int main()
{
derived d;
d.g();
}
実行結果は以下の通りです。
derived::f
ただし、スコープ解決を行う事で隠蔽された基底クラスのメンバを呼び出す事は可能です。
#include<iostream>
struct X{
void f(){std::cout<<"X::"<<__func__<<std::endl;}
};
struct derived:X{
void f(){std::cout<<"derived::"<<__func__<<std::endl;}
void g(){X::f();} // スコープ解決によってX::fを呼び出し
};
int main()
{
derived d;
d.g();
}
実行結果は以下の通りです。
X::f
尚、隠蔽しても例えばそれらの関数がオーバーロード可能な関数であれば以下のようにして継承元から引き出す事も可能です。
#include<iostream>
struct X{
void f(int)
{
std::cout<<"X::"<<__func__<<std::endl;
}
};
struct derived:X{
using X::f; // 隠蔽されたX::fを宣言させる
void f(double)
{
std::cout<<"derived::"<<__func__<<std::endl;
}
};
int main()
{
derived d;
d.f(42);
d.f(4.2);
}
実行結果は以下の通りです。
X::f
derived::f
using X::fという記述は継承コンストラクタの記述と同じです。継承コンストラクタの説明では、コンストラクタだけをusingさせて引き出していましたが、このようにメン関数もusingして機能を引き出す事ができます。
さて、このような隠蔽の機能を使うか否かは果たしたい機能によって適切であるかどうかを考慮する必要がありますが、上記のようにpublic継承している場面では、隠蔽してしまうとその意味を成さない事になってしまう事が多いです。その理由は、本章を順に読み進めていく事で理解できるようになるでしょう。
9.6.4 継承を禁止する
継承を禁止させる事も可能です。以下のように記述します。
struct X final{
// ...
};
クラスの宣言時にfinalキーワードを用いる事でそのクラスを継承する事が禁じられます。クラスの宣言時にfinalキーワードが付与されたクラスを継承しようとすると
struct X final{};
struct derived:X{};
GCC 7.1.0では以下のようなエラー文を出力しました。
error: cannot derive from 'final' base 'X' in derived type 'derived'
struct derived:X{};
^~~~~~~
9.6.5 スライシング
まず定義として、派生クラスは、基底クラスよりサイズが大きくなります。これは、派生クラスは、基底クラスのサイズに追加のメンバ変数うを持っている可能性があるため、断定できる条件なのです。つまりクラスBaseという基底クラスからクラスDerivedが派生クラスとして定義されていた場合、両者の関係は必ずsizeof(Base) <= sizeof(Derived)がtrueとなります。
継承関係にあるクラス同士は、型変換が効くので以下のようなコードを記述する事もできます。
struct Base{};
struct Derived:Base{};
int main()
{
Base base=Derived(); // スライシング。派生クラスのインスタンスで基底クラスを初期化
}
しかし、このように基底クラス型のオブジェクトを派生クラスのオブジェクトで初期化すると、基底クラスは派生クラスの全ての情報を扱う事ができないため(派生クラスは基底クラスよりもサイズが大きい)、派生クラスに固有な情報が失われてしまいます。これを、スライシングと言います。
スライシングは、意図せず記述した場合明らかにバグとなりますので防止する必要がありますが、ここでの問題は実態として派生クラスのオブジェクトで初期化するために起きていますから、この場合基底クラスのオブジェクトではなく派生クラスのオブジェクトで派生クラスのオブジェクトを初期化する必要があります。
尚、ポインターや参照の場合は問題ありません。単に指し示すだけなので、データそのものが失われる事はないのです。
struct Base{};
struct Derived:Base{};
int main()
{
Base* ptr=new Derived();
delete ptr;
const Base& ref=Derived();
}
なぜわざわざ基底クラス型のポインターや参照で派生クラスのオブジェクトをポイントしておくのか、その利点については「9.6.7 仮想関数とオーバーライド」で明らかとなりますのでそれは一旦置いておくとして、実はこのように基底クラス型のポインターや参照として派生クラスをポイントしている場合でも、スライシングとはまた別の問題が発生してしまっているのです。何が起きてしまっているのかは、デストラクタの挙動を追いかける事で判明します。
#include<iostream>
struct Base{
~Base(){std::cout<<__func__<<std::endl;}
};
struct Derived:Base{
~Derived(){std::cout<<__func__<<std::endl;}
};
int main()
{
Base* ptr=new Derived();
delete ptr;
}
実行結果は以下の通りです。
~Base
なんと、派生クラスのデストラクタが呼び出されないのです。指し示している実態はDerivedのインスタンスですが、delete の対象はポインターの型Baseを元に動作するため、基底クラス側のデストラクタだけが呼び出される動作となってしまうのです。このような問題が起きないためには、基底クラスのポインター型でヒープ上に生成された派生クラスのオブジェクトをそもそも指し示さなければ良いのですが、これから解説する基底クラスのポインターで派生クラスのインスタンスを管理する事の利点を踏まえると、どうも捨てがたい機能ではあるのです。
この問題は、仮想関数という機能を用いる事で回避する事が可能です。
9.6.6 仮想関数とオーバーライド
まずはじめに、重要なルールをここで述べておきます。それは、基底クラス型のポインターは、その派生クラス型のオブジェクトをポイントする事ができるが、派生クラス型のポインターは、基底クラス型のオブジェクトをポイントする事ができないという事です。
struct Base{};
struct Derived:Base{};
Base* ptr0 = new Base(); // OK. Base のポインター型で Base 型のオブジェクトをポイントする
Derived* ptr1 = new Derived(); // OK. Derived のポインター型で Derived 型のオブジェクトをポイントする
Base* ptr2 = new Derived(); // OK. Base のポインター型で Derived 型のオブジェクトをポイントする
Derived* ptr3 = new Base(); // NG. 派生クラス型のポインターで基底クラス型のオブジェクトをポイントする事はできない
これが何故なのかは、メモリレイアウトを考えると明快です。以下に図を示します。
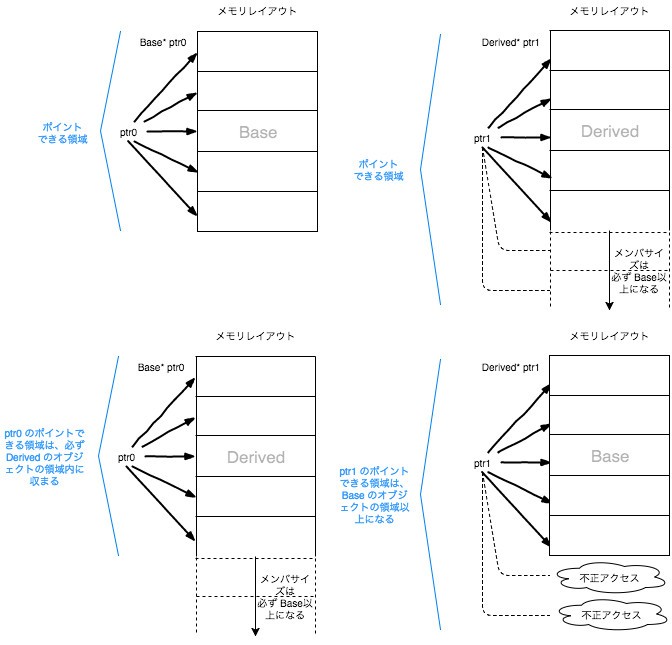
このように、派生クラスは、必ず基底クラス以上のメンバを持つ事が言えます。つまり、基底クラス型のポインターは派生クラス型のオブジェクトにアクセスする際、必ず派生クラス型のオブジェクトの範囲内にアクセスされる事が保証できるため、基底クラス型のポインターが派生クラス型のオブジェクトをポイントできる事は自然であると言えます。
反対に、派生クラスは基底クラス以上のメンバを持つのですから、基底クラス型のオブジェクトをポイントできてしまうと、基底クラスの取り扱う領域の範囲外までアクセスできてしまうのです。そう考えると、この制約もとても自然です。
以上を踏まえてさらに以下のコードを見てみましょう。尚、virtual ~dog()=default;については現段階では気にしなくて大丈夫です。
#include<iostream>
struct dog{
void call(){std::cout<<"bowwow"<<std::endl;}
virtual ~dog()=default;
};
struct cat:dog{
void call(){std::cout<<"mew"<<std::endl;}
};
int main()
{
dog* ptr1=new dog(); // #1
ptr1->call();
dog* ptr2=new cat(); // #2
ptr2->call();
delete ptr1;
delete ptr2;
}
実行結果は以下の通りです。
bowwow
bowwow
このコードは全くもってよくありません。#1ではdogクラスをヒープ上にインスタンス化しその後call関数を呼び出しているため、bowwowと出力されるのは意図した動作です。しかし、その後の#2で、catクラスで定義されているcat::call関数を呼び出したいところですが、出力からわかるように、dog::callを呼び出してしまいました。何故このようになってしまうかというと、型はあくまでdog*であり、そこには継承先であるcatの型情報が全くないため、実際のオブジェクトによって呼び分けたりする事ができないためです。これを意図した通りに動作させるためには、基底クラスのdog::callを仮想関数として定義します。
#include<iostream>
struct dog{
virtual void call(){std::cout<<"bowwow"<<std::endl;} // callを仮想関数として定義する
virtual ~dog()=default;
};
struct cat:dog{
void call(){std::cout<<"mew"<<std::endl;}
};
int main()
{
dog* ptr1=new dog();
ptr1->call();
dog* ptr2=new cat();
ptr2->call();
delete ptr1;
delete ptr2;
}
実行結果は以下の通りです。
bowwow
mew
出力の通り、意図した通りに動作しました。このように、関数宣言時にvirtualキーワードが付与された関数を仮想関数と言います。仮想関数を定義すると何が起きるのかというと、仮想関数テーブルというものがコンパイラによって暗黙的に生成されます。仮想関数テーブルは、ある仮想関数を呼び出した時に、実際の呼び出し元のオブジェクトの型によって、どの関数が呼ばれるのかの情報が書き込まれているものです。プログラマには直接的に見えない、クラスの隠しメンバ変数としてその情報を持つようになります。virtualキーワードの付与によって仮想関数を宣言し、仮想関数テーブルが作成される事で、実際のオブジェクトによってそのオブジェクトの型が持つメンバ関数を呼び出す事ができるのです。これを関数のオーバーライドと言います。尚、基底クラスの関数を仮想関数として宣言し、それを派生クラスの関数でオーバーライドしている時、派生クラスのオーバーライドした関数も仮想関数として定義されます。よって以下のように、オーバーライドする関数の宣言でvirtualを付与する事もできます。
struct dog{
virtual void call(){std::cout<<"bowwow"<<std::endl;} // callを仮想関数として定義する
virtual ~dog()=default;
};
struct cat:dog{
virtual void call(){std::cout<<"mew"<<std::endl;} // virtualを明記。動作と意味は全く変わらない
};
また全く動作は変わりませんが、virtualキーワードを敢えて明記した方が良いとする考え方もあり>ます。
何故このような考え方があるかといえば、派生クラスの該当関数が仮想関数としてオーバーライドしているのかそのシグネチャだけからは判断する事が出来ないためです。しかし、もしそのような目的でvirtualキーワードを用いるのであれば、overrideというキーワードを用いて関数宣言するべきです。
struct Base{
virtual void call(){std::cout<<"bowwow"<<std::endl;} // callを仮想関数として定義する
virtual ~dog()=default;
};
struct Derived:Base{
~()override{std::cout<<__func__<<std::endl;} // overrideキーワードによってオーバーライドしてい>る旨を明記する
};
overrideキーワードは、基底クラスにある仮想関数をオーバーライドしているという旨を明記するためのキーワードであり、関数の仮引数リストの後に記述します。
ところで、先程、「プログラマには直接的に見えない、クラスの隠しメンバ変数として情報を持つ」と言いました。という事は、その分クラスのサイズが増加するのではと思うかも知れません。まさにその通りで、仮想関数が定義されたクラスはサイズがその分増加します。
#include<iostream>
struct X{
virtual void f(){} // 仮想メンバ関数
};
struct Y{
void f(){} // 仮想でないメンバ関数
};
int main()
{
std::cout<<sizeof(X)<<std::endl;
std::cout<<sizeof(Y)<<std::endl;
}
筆者の環境では実行結果は以下の通りです。
8
1
よって、仮想関数テーブルの機能を特別使わないのであれば、仮想関数を宣言する事は無駄であると言えます。
それでは漸くですが、9.6.5の最後で提示した問題、デストラクタが呼ばれないという問題に対する対処を行いましょう。問題は以下のようなコードでデストラクタが呼ばれないというものでした。
#include<iostream>
struct Base{
~Base(){std::cout<<__func__<<std::endl;}
};
struct Derived:Base{
~Derived(){std::cout<<__func__<<std::endl;}
};
int main()
{
Base* ptr=new Derived();
delete ptr; // ~Baseのデストラクタしか呼ばれない
}
この問題は、デストラクタが仮想関数として定義されておらず、オーバーライドができない事によって起きているのです。つまり、先程まで述べてきたメンバ関数をvirtualにした場合と同じように、基底クラスのデストラクタをvirtual宣言する事でこの問題を回避できます。
#include<iostream>
struct Base{
virtual ~Base(){std::cout<<__func__<<std::endl;}
};
struct Derived:Base{
~Derived()override{std::cout<<__func__<<std::endl;}
};
int main()
{
Base* ptr=new Derived();
delete ptr;
}
実行結果は以下の通りです。
~Derived
~Base
このようなデストラクタを仮想デストラクタと呼びます。派生クラスのシグネチャからオーバーライドしている事を明記するためにoverrideというキーワードを用いて関数を宣言/定義するのも良いでしょう。
struct Base{
virtual ~Base(){std::cout<<__func__<<std::endl;}
};
struct Derived:Base{
~Derived()override{std::cout<<__func__<<std::endl;}
};
尚、仮想関数に設定しオーバーライドする事はコンストラクタ以外の関数に行う事ができます。よって、以下のようなコードを記述する事はできません。
struct Base{
virtual Base(); // エラー!コンストラクタを仮想関数としオーバーライドする事はできない
};
しかし仮想関数に対してdefaultやdelete指定などを行う事はできます。
struct Base{
virtual ~Base()=default; // デフォルトデストラクタの動作で仮想関数とする
};
struct Derived:Base{
~Derived()override=default; // 仮想デフォルトデストラクタはオーバーライドしている
};
struct Base{
virtual void f()=delete; // 仮想関数fはdeleteされている
};
struct Derived:Base{
void f()override=delete; // オーバーライドした仮想関数fはdeleteされている
};
9.6.7 抽象クラスと純粋仮想関数によるインタフェース
仮想関数のオーバーライドによって、処理の内容を派生クラス側で制御する事ができました。しかし、例えば基底クラスが継承されて処理を上書きする(オーバーライドされる)前提であった場合どうでしょうか。そのような前提はどのようなシーンで起きるかというと、例えば実行する大まかな内容は同じでも内部処理が実際のオブジェクトの型によって変動する場合です。
struct Drawer{
virtual void draw(){ /* ... ? */ }
virtual ~Drawer()=default;
};
struct Circle:Drawer{
void draw()override{ /* 円を描く処理... */}
};
struct Square:Drawer{
void draw()override{ /* 四角形を描く処理... */}
};
struct Triangle:Drawer{
void draw()override{ /* 三角形を描く処理... */}
};
int main()
{
Drawer* a=new Circle();
a->draw(); // 円を描く...
Drawer* b=new Square();
b->draw(); // 四角形を描く...
Drawer* c=new Triangle();
c->draw(); // 三角形を描く...
Drawer* d=new Drawer();
d->draw(); // Drawerは何を描く...?
delete a;
delete b;
delete c;
delete d;
}
クラスDrawerは「描く者」というそれ単体では意味をなさないクラスであり、それを継承して各クラスで関数drawをオーバーライドさせるためのクラスです。Circleは円を描き、Squareは四角形を描き、Triangleは三角形を描きます。しかしこの場合、Drawerクラスは何をするべきでしょうか?Drawerクラスの関数drawは、継承先でオーバーライドされる事を前提としているので、それ単体では何の意味も持てず、コードの記述に困ってしまいますし、Drawer関数を実体化されても何の意味もないので実体化される事自体を防ぎたいところです。
今まで学んできた内で考えられる対策は幾つかありますが、それらはどれもその意味を直接的に示すものではないでしょう。例えば、該当関数にassertを仕込み、コンストラクタをprotectedにしてしまう方法です。
#include<cstddef>
#include<cassert>
struct Drawer{
virtual void draw(){ assert(false); } // コンストラクタがprotectedなため呼び出される事はないが意図を示すためにassertを仕込む
virtual ~Drawer()=default;
protected:
Drawer()=default;
};
struct Circle:Drawer{
void draw()override{ /* 円を描く処理... */}
};
struct Square:Drawer{
void draw()override{ /* 四角形を描く処理... */}
};
struct Triangle:Drawer{
void draw()override{ /* 三角形を描く処理... */}
};
int main()
{
Drawer* a=new Circle();
a->draw(); // 円を描く...
Drawer* b=new Square();
b->draw(); // 四角形を描く...
Drawer* c=new Triangle();
c->draw(); // 三角形を描く...
Drawer* d=new Drawer(); // エラー!protectedアクセス領域にあるコンストラクタは呼び出せない
//d->draw();
delete a;
delete b;
delete c;
//delete d;
}
Drawer単体ではインスタンス化出来ないため、Drawer::drawが呼び出される心配もなくなりましたが、これでも問題は残ります。それは、継承先で関数drawをオーバーライドしなくてもコンパイルが通ってしまう点です。
struct Drawer{
virtual void draw(){ assert(false); } // コンストラクタがprotectedなため呼び出される事はないが意図を示すためにassertを仕込む
virtual ~Drawer()=default;
protected:
Drawer()=default;
};
struct Circle:Drawer{};
struct Square:Drawer{};
struct Triangle:Drawer{};
//...
Drawerクラスは継承先で関数drawをオーバーライドされる前提であるのにも関わらずこのようなコードが書けてしまう事はとても危険です(後に学習する、「テンプレート」の知見を得れば、実は強制的に派生クラスへ関数の定義を強制する事ができたりもします)。
このような場合に、純粋仮想関数という機能を用いる事で全ての問題が解消できます。まず、純粋仮想関数は以下のように記述します。
struct Drawer{
virtual void draw()=0; // #1
virtual ~Drawer()=default;
};
struct Circle:Drawer{
void draw()override{ /* 円を描く処理... */}
};
struct Square:Drawer{
void draw()override{ /* 四角形を描く処理... */}
};
struct Triangle:Drawer{
void draw()override{ /* 三角形を描く処理... */}
};
int main()
{
Drawer* a=new Circle();
a->draw(); // 円を描く...
Drawer* b=new Square();
b->draw(); // 四角形を描く...
Drawer* c=new Triangle();
c->draw(); // 三角形を描く...
delete a;
delete b;
delete c;
}
#1が、純粋仮想関数です。関数のシグネチャの後に=0と記述する事でその関数を純粋仮想関数とする事ができます。純粋仮想関数が宣言されたクラスは、それ単体では実体化する事が出来ず、かつ継承先へその関数をオーバーライドする事を強制させます。
struct Drawer{
virtual void draw()=0;
virtual ~Drawer()=default;
};
struct Circle:Drawer{};
int main()
{
Circle(); // エラー!Circleクラスはdraw関数をオーバーライドしていない
Drawer(); // エラー!純粋仮想関数を持つクラスは実体化できない
}
純粋仮想関数のみで構成されたクラスをインタフェースクラスや、抽象クラスと言います。
尚、デストラクタのみは特別で純粋仮想関数の内部実装を定義する事ができます。
struct Base{
virtual ~Base()=0;
};
Base::~Base(){} // 純粋仮想デストラクタのみ内部実装を定義する事ができる。
struct Derived:Base{};
int main()
{
Base(); // エラー!依然として純粋仮想関数を持つクラスは実体化する事ができない
}
これを純粋仮想デストラクタと言います。純粋仮想デストラクタは、定義において、上記のように宣言と定義を分離しなければなりません。つまり以下のようには記述できません。
struct Base{
virtual ~Base()=0
{
// ...というようには書けない
}
これは何に使うのかと言うと、該当クラスをインタフェースクラスとして定義したいが、純粋仮想関数にできるメンバが1つもない場合などで用います。
9.6.8 多重継承と仮想継承
二つ以上のクラスから継承する事もできます。これを多重継承と呼びます。
struct A{};
struct B{};
struct C:A,B{}; // Cは多重継承
多重継承の際にはカンマ(,)でクラスを区切ります。多重継承の際には、継承するそれぞれのクラスに対して以下のようにアクセスレベルを設定できます。
struct A{};
struct B{};
struct C:protected A,private B{};
さて、多重継承は以下のような構造となった時に少し厄介な問題に直面します。
#include<iostream>
struct A{
void f(){std::cout<<__func__<<std::endl;}
};
struct B:A{};
struct C:A{};
struct Derived:B,C{};
int main()
{
Derived a;
a.f();
}
このコードはコンパイルに失敗します。GCC 7.1.0では、以下のようなエラー文を出力しました。
In function 'int main()':
error: request for member 'f' is ambiguous
a.f();
^
candidates are: 'void A::f()'
void f(){std::cout<<__func__<<std::endl;}
^
note: 'void A::f()'
エラー文では"ambiguous"、つまり曖昧であると述べています。まず、継承構造は以下の図の通りです。
この継承関係によって、Derivedクラスをインスタンス化した段階でクラスAの実態が二つ存在する事にこの問題の起因があります。クラスBもクラスCも、共にクラスAを継承しています。それをDerivedクラスで一つにまとめているため、関数fの呼び出し時にBから継承されたA::fなのか、Cから継承されたA::fなのかが曖昧となってしまうのです。
これはどうすれば良いかというと、単純にスコープ解決を行えば曖昧さを取り除く事ができます。
#include<iostream>
struct A{
void f(){std::cout<<__func__<<std::endl;}
};
struct B:A{};
struct C:A{};
struct Derived:B,C{};
int main()
{
Derived a;
a.B::f();
a.C::f();
}
a.B::f()によってBから構築されたAの関数fを、a.C::f()によってCから構築されたAの関数fを呼び出しています。
このような継承関係で、Aの実態が二つである事を最も捉えられるのは内部にデータを持っている時でしょう。
#include<iostream>
struct A{
constexpr A(int x):data(std::move(x)){}
int data;
};
struct B:A{
using A::A;
};
struct C:A{
using A::A;
};
struct Derived:B,C{
constexpr Derived(int x):B(std::move(x)),C(std::move(x)){}
};
int main()
{
Derived a(42);
a.B::data=100;
a.C::data=200;
std::cout<< a.B::data <<std::endl;
std::cout<< a.C::data <<std::endl;
}
実行結果は以下の通りです。
100
200
このように、同名のデータであっても、BとCがそれぞれAを継承している事でその内部データもその分当然ながらインスタンス化されます。
しかし、このような継承関係でありながら共通のクラスの実態をたった1つのみにしたい場合もあるでしょう。そういった場合には仮想継承という機能を使います。仮想継承は、基底クラスの指定時で、virtualキーワードを付与します。
#include<iostream>
struct A{
int data;
};
struct B:virtual A{};
struct C:virtual A{};
struct Derived:B,C{};
int main()
{
Derived a;
a.B::data=100;
a.C::data=200;
std::cout<<a.B::data<<std::endl;
std::cout<<a.C::data<<std::endl;
}
実行結果は以下の通りです。
200
200
実態が二つであればa.B::dataの出力で100と出力されるはずですが、どちらも200と出力されました。つまり、実態が一つであると言う事になります。
また、実態が一つなので、スコープ解決を行わなくてもデータに対するアクセスは曖昧にはなりません。
#include<iostream>
struct A{
int data;
};
struct B:virtual A{};
struct C:virtual A{};
struct Derived:B,C{};
int main()
{
Derived a;
a.data=100;
std::cout<<a.data<<std::endl;
}
実行結果は以下の通りです。
100
9.6.9 is-a、has-a関係
継承という機能を利用する事で得られる恩恵の一つとして、差分プログラミングが行えるという点があります。差分プログラミングとは、既に定義されたクラスが持っている機能をもう1度書き直すことを避け、そのクラスを継承して継承先ごとに必要な部分だけを追加で書き足す事で、同じコードの散乱を防止する事ができます。ただし、このような差分プログラミングを行う上で、is-a関係を尊重すべきであるという考え方があります。
is-a関係とは何なのでしょうか。is-a関係とは、継承関係にあるクラス同士が、「Derived is a Base(Derived は Base である)」と言える関係を言います。例えば、以下のようなクラスはis-a関係にあると言えます。
struct Bird{ // 鳥をモデル化したクラス
virtual void fly()=0; // "飛ぶ"という鳥の機能
};
struct Crow:Bird{ // is-a関係。カラスは鳥である。
void fly()override;
};
一方、以下のようなクラスはis-a関係であるとは言えません。
struct Wing{ // 翼をモデル化したクラス
void fly();
};
struct Bird:Wing{/* ... */}; // is-a関係ではない。翼は鳥ではない。
struct Crow:private Bird{ // protectedもしくはprivate継承の場合、機能が絞られる事となるためis-a関係にはなれない。
「翼は鳥である」という文は成立しませんから、この関係はis-a関係とは言えません。
is-a関係と対比して言われるのが、has-a関係です。
struct Wing{ // 翼をモデル化したクラス
void fly();
};
struct Bird{
Wing wing;
};
Birdクラスは上記の通りクラスWingの機能を元に構成されます。クラスが別のクラスの機能の上に成り立っている関係をhas-a関係と言います。
9.6.10 EBO
EBOとは、Empty Base Optimizationの略です。EBOは、内部にデータを持たないクラスを継承した際に行われる最適化です。以下のコードを見てください。
#include<iostream>
struct X{};
int main()
{
std::cout<<sizeof(X)<<std::endl;
}
実行結果は以下の通りです。
1
なんと、クラスXは何もデータを持っていないのにも関わらず、実際のサイズは1であるというように出力されています。これは何故かと言うと、データのないクラスをインスタンス化した際に、そのインスタンス化したオブジェクトのアドレスを取得できるようにするためです。そのオブジェクトのサイズが0では、アドレスを取得する事は当然ながらできません。よって、C++において最小単位である1バイトサイズのオブジェクトとしてインスタンス化されるのです。
しかし、このクラスを継承させて見てみると、少し面白い事が起きます。
#include<iostream>
struct X{};
struct Y:X{};
int main()
{
std::cout<<sizeof(Y)<<std::endl;
}
実行結果は以下の通りです。
1
まず、クラスXは何もデータを持ちませんが、先ほど述べたようにアドレスを取得できるように、最低限のサイズである1バイトが割り振られるはずです。そして、クラスYも何もデータを持たないため、最低限のサイズである1バイトが割り振られ、その合計として2バイトというように出力される...かと思いきや、実際の出力はなんと1バイトとなっています。
これがEBO最適化というものです。まず、C++の言語規格として、何もデータを持たない型が別の型を継承していて、継承元の型が既にサイズを持っている場合や、それとは逆に何もデータを持たない型の継承先がサイズを持っている場合、その何もデータを持っていないクラス分の追加サイズは無くしても良いように定められているため、その原則に則った最適化が行われます。これが、EBOという最適化です。
EBOは、あくまで言語仕様として必須ではないため、コンパイラによってはEBOが行われない可能性がありますが、大抵のコンパイラはEBO最適化を行います。
このように、EBOは無駄な領域を取らない便利な最適化ですが、継承関係によってはEBOを適用できない場合があります。例えば以下の場合はEBOを行う事ができません。
#include<iostream>
struct A{};
struct B:A{};
struct C:A{};
struct Derived:B,C{};
int main()
{
std::cout<<sizeof(Derived)<<std::endl;
}
実行結果は以下の通りです。
2
A、B、Cも全て全てデータを何も持っていませんが、EBOが効いていません。これは何故かというと、多重継承の項で説明したように、異なるクラスがそれぞれ同じ基底クラスを継承している時、双方共に異なる実態を持つからです。異なる実態を持つと言う事は、それぞれを最適化で無くす事はできないのです。
と言う事は、基底クラスの実態を複数にしなければEBO最適化が行われるので、仮想継承を行えば良いのでは?と思うかもしれません。しかし残念ながら、仮想継承する事によってvtableが構築され、データが何もないクラスには成らなくなってしまいますから、EBOは効きません。
#include<iostream>
struct A{};
struct B:virtual A{};
struct C:virtual A{};
struct Derived:B,C{};
int main()
{
std::cout<<sizeof(Derived)<<std::endl;
}
筆者の環境では以下のように出力されました。
16
では、多重継承の場合、EBOの恩恵を受ける事はできないのかというと、実はそうではないのです。その方法は、「第11章 テンプレート」にて明らかとなりますので、楽しみにしていてください。