16.4 アライメント
この項では、アライメントについて説明します。
アライメントとは、実は特別な言語機能という訳では全くなくて、私たちがプログラミングを行ってそれを実行するのには欠かせないCPUとメモリの都合から成る概念です。C++は、他の言語(特に高級言語)と比較すると、低レイヤーな部分を操作する事ができる言語なので、アライメントという概念に直接的な関わりを持つ事が多いかもしれません。
というわけで、アライメントの概念そのものはC++言語から起因する特別な機能というわけではないのですが、理解できる事に越したことはないので、この項で説明することにします。
16.4.1 アライメントとは
アライメントとは一言で言えば、メモリ上に配置されるデータがどのような区切り/境界で置くかを全般的に示した語です。
そもそも、CPUは、基本的に整数型と浮動小数点型しか扱いません。それぞれ、例えば C++ の型で言えば、signed/unsignedでshort/long/long longなintだったり、float、doubleのような型です。
文字(char)は、本書の冒頭でも述べた通りただの 1 バイトの整数です。
ところで、最近のCPUの殆どは、メモリ上のデータを1バイト単位で読み書きできます(一昔前は、word単位でしか読み書きができなかった)。
つまりメモリは、巨大なバイト配列と考えることができますね。
そしてその巨大なバイト配列であるメモリは、32ビット CPUの場合、32本の電線の束(データバス)と繋がれています(32ビットCPUと謳いながら64本のデータバスで繋ぐCPUもあるのですが、話を単純化するため、そのような例外は踏まえず、端的な32ビットバスを前提に話を進めます)。
CPUはこのデータバスを使ってメモリからデータを読み込みますが、一度に読み込める量は順次32ビットずつ、つまり4バイトです(C/C++言語規格の1バイト単位ではない事に注意してください)。
さて、ここまでの前提を踏まえて、まずはchar型(1バイト)をメモリ領域上に確保する場合を考えて見ましょう。char型は1バイトですね。そして一度にCPUがメモリから読み込めるデータ量は、上記の前提に従うと、4バイトずつです。
よって、char型(1バイトデータ)は、メモリのどこに配置したとしても一度のメモリ読み込みで漏れなく必ず読み込めるという事が言えます。
次に、int型をメモリに配置する場合を考えて見ましょう。ここでは、以下がtrueである事を前提とします。
sizeof(int) == 4
つまり、int型は4バイトの前提です(std::int32_tまたはstd::uint32_tを前提とすると話が早いのですが、現時点では詳しく触れていないためintを 4 バイトと仮定して話を進めます)。
4バイトのデータをメモリ上に配置しようとした時、char型とは違って一つ考えなくてはならない問題があります。char型は1バイトなので一つのアドレスだけで済みます。当然ですね。
しかし、int型は4バイトです。4バイトのデータは、4つのアドレス部分を使って、データを表現する必要があります。
メモリに対するアクセスは、とても処理時間のかかる行為です。ですから、できる限りメモリ読み込みの回数を少なくして、一度でまとめてデータを読み込みたいところです。
そこで、効率的に読み込めるように、int型のデータを4バイト境界にアラインします。
4バイト境界にアラインとは、つまり、int型のデータを配置する、4バイト中の先頭1バイトのメモリアドレスを、4の倍数になるように配置するという事です。
こうする事で、下図のように、一度でint型のデータを全て読み込む事ができますね。
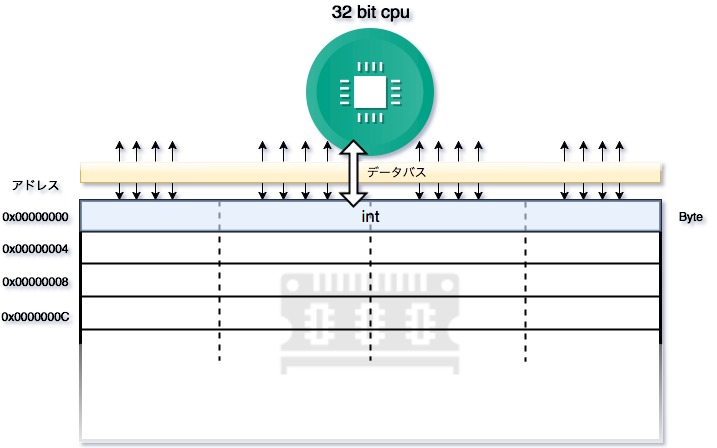
例えば、ここでint型のアラインメントを4バイトよりも小さく設定したら、実際の値はメモリから正常に読み込めるのでしょうか。
この答えは、一概には言えません。CPUによってそれを許容している場合と、エラーとして対処する場合と、どちらも存在します。
しかし、通常のアライメントに違反したデータの配置は、もしそのようなコードが動いたとしても、非効率的なメモリ読み込みをする事が多いです。例えば4バイトのデータが4バイト境界にアラインされておらず、それぞれ2バイトずつが連続していない別の場所にある場合、メモリの読み込み回数が1回増加する事になるのです。
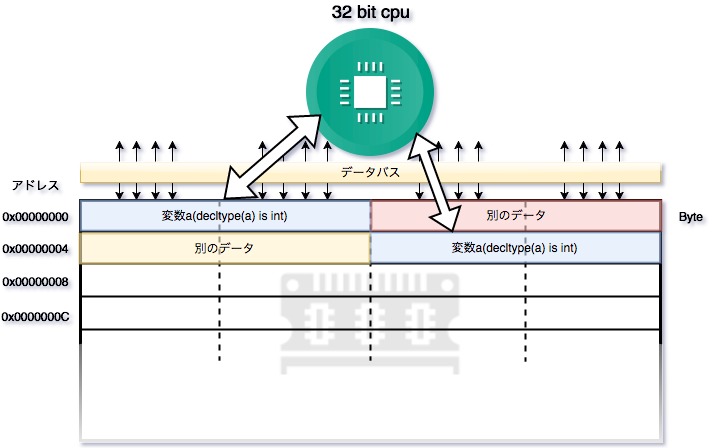
よって、適切なアラインを取るという事は、上記の通り効率的なアクセスのための他にも、そもそもアラインメントされていないデータ自体を受け付けないCPUとの互換性を考えると、とても大切な事である事が言えます。
このように、CPUが一度に読み込むデータ量を考慮して、メモリ上に配置するデータの先頭アドレスをある値Nの倍数にする事を「Nバイトにアラインする」と言います。
アラインメント値は、プリミティブ型の場合、型のサイズと同等であることが多いです(例外もあります)。以下のコードを実行して確認してみましょう。
#include<cstdio>
#include<boost/type_index.hpp>
template<class T>
void disp_size_align()
{
std::printf(
"type: %s\nsizeof: %zu\nalign: %zu\n",
boost::typeindex::type_id<T>().pretty_name().c_str(),
sizeof(T),
alignof(T)
);
}
int main()
{
disp_size_align<char>();
disp_size_align<short int>();
disp_size_align<int>();
disp_size_align<float>();
disp_size_align<double>();
}
筆者の環境では以下のように出力されました。
type: char
sizeof: 1
align: 1
type: short
sizeof: 2
align: 2
type: int
sizeof: 4
align: 4
type: float
sizeof: 4
align: 4
type: double
sizeof: 8
align: 8
16.4.2 パディング
ここまでは、単純なプリミティブ型の話しでした。ここからは、構造体などの複合データ型に関するサイズとアライメントの関係を見ていきます。
まず、以下のコードを見てください。
struct X {
int a;
char b;
};
さて、ではこの構造体Xのアラインメント、またサイズは何バイトでしょうか。
先ほどのコードで使ったdisp_size_align関数を使って見て見ます。
// disp_size_align...
// 先と同様
struct X {
int a;
char b;
};
int main()
{
disp_size_align<X>();
}
実行結果は以下の通りです。
type: X
sizoef: 8
align: 4
まずsizeofの結果を見て見ましょう。なんとX型のサイズは8となっています。先ほど、intは4バイト、charは1バイトという前提の基、と言いましたから、4+1で5バイトの構造体であるはずです。これは、不思議ですね。
そしてalignの方も、4バイトとなっています。どうやら、この4バイトというのはintのサイズの事のようですが、一概にintのサイズが構造体のアライメントになるとも限りません。
この謎は、アライメントと深く関係があります。ここで、もし例えば5バイトの構造体として定義したらどのようになるか考えて見ましょう。
そうです、5バイトの構造体として定義された場合、CPUによっては、4バイトずつ読み込めるようにアラインメントされていないとして、エラーとして対処する場合があるのです(対応しているCPUの場合、前述した通り二度メモリアクセスを行う事でデータを取得しようとするでしょう)。
そのような処理系依存なデータ構造をデフォルト動作として生み出すわけにはいきません。そこで、対応している値(2の冪乗)でアラインする必要があります。そしてその値は、内包するデータ型の内最も大きいアラインに合わされます。より厳密に説明すると、コンパイラがある型TとUの両方を含むオブジェクトを作成しT + Uの2つのインスタンスが1つずつ配置された場合、各メンバTまたはUはそれ自身でなければならないため、そのためには、その合計サイズが各メンバの配置の倍数でなければならないのです。この場合、intが最も大きいアラインのデータ型であり、全てのメンバの倍数となれるので、その値に合わされます。
そして構造体のサイズは、アライメントの倍数でなければなりません。そこで、どうなるかというと、アラインメントの倍数に切り上げられるのです。切り上げにはパディングが挿入されます。
つまり、上記のsizeofが示すサイズは、intの4バイト+charの1バイトで5バイトなので、そこから最も大きいアラインメントの倍数(この場合4バイト)に切り上げて、結果、8となります。
理解を助けるために、別の例も見て見ましょう。以下のような構造体はどのようなアラインで、sizeofは何になるでしょうか。
struct X {
double a;
char b;
};
結果は以下の通りです。
type: X
sizoef: 16
align: 8
最も大きいアラインはdoubleです。doubleは8バイトを必要とするため、8バイトのアラインが示されています。という事は型Xはアラインの倍数とならなければならないので、doubleの8バイト+charの1バイト、合計9バイトから8の倍数で繰り上げて、16バイトとなります。ではもしかすると、パディングを考慮しつつメンバを増やしたら、構造体のサイズは変わらない(パディングが減るだけ)かもしれないと思いいましたでしょう。やってみましょう。
struct X{
double a[2]; // doubleを二つにする
}
結果は以下の通りです。
type: X
sizoef: 16
align: 8
その通りです!ご覧の通り、二つのdoubleと一つのdouble、一つのcharを構造体として包めた場合、アラインメントの制約によってパディングが詰められるため、双方のサイズは全く同じになるのです。
このような事を知ると、例えば状況にもよりますが、データ量を最大限にまで抑える事を考えた場合、パディングがどうせ取られるのであれば、その分の領域を確保しておき、その領域に何か他の有用なデータを入れて置くなどといった最適化が考えられるようになります。
また、内包するメンバをどの順番で宣言するかで、パディングが余計に加わる事があります。
struct X{
char a[6];
int b;
short c;
};
このXのアライメントとサイズを見て見ましょう。
type: X
sizoef: 16
align: 4
まずcharが6バイト、intが4バイト、そしてshortが2バイトです。全て足すと12バイトです。
12は、この中で最も大きいアラインの4の倍数です。よって、これは、全く無駄のない構造体に見えるかもしれません。
しかし、実際のサイズは16バイトと出力されています。何故か、さらに繰り上がっているのです。
問題は、構造体内のメンバ変数が配置される仕組みと、intの前にある領域とのアラインメントの関係から来ています。
まず、構造体のメンバ変数は通常、連続した領域に確保されます。
という事はchar a[6]の後に、int bの4バイトを配置するという事になります。この時、6バイトというサイズは、intから考えると、4バイト+2バイトというように捉えられるのです。つまり、char a[6]の末尾の2バイト分が、intにとってとてもキリの良いアライメントとは言えないのです。もしその末尾2バイト分からintの領域4バイト分を取ってしまうと、4の倍数にアラインを揃えるという規則が破綻してしまいます。よって、その規則を守るために、char a[6]の後に、2バイト分のパディングを挿入し、intにとって区切りの良いメモリアドレス(4でアライメントされた場所)から領域の確保が行われるのです。
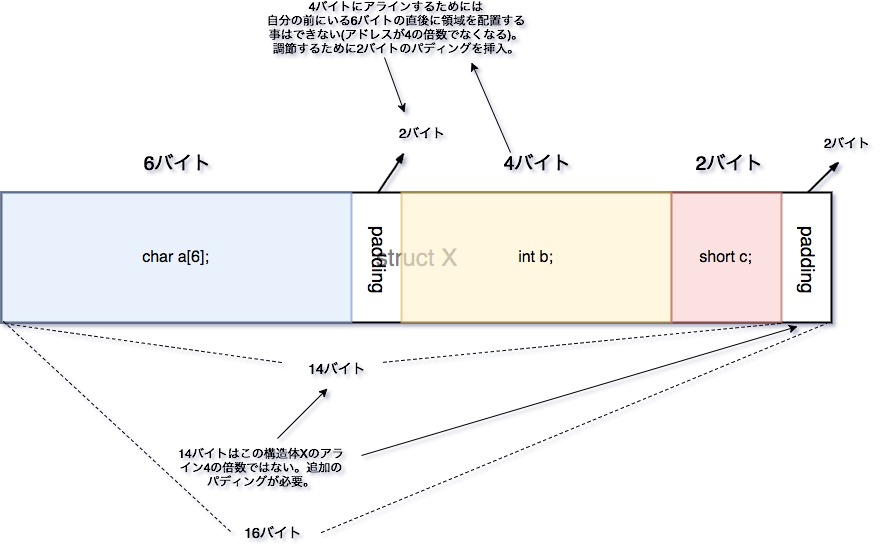
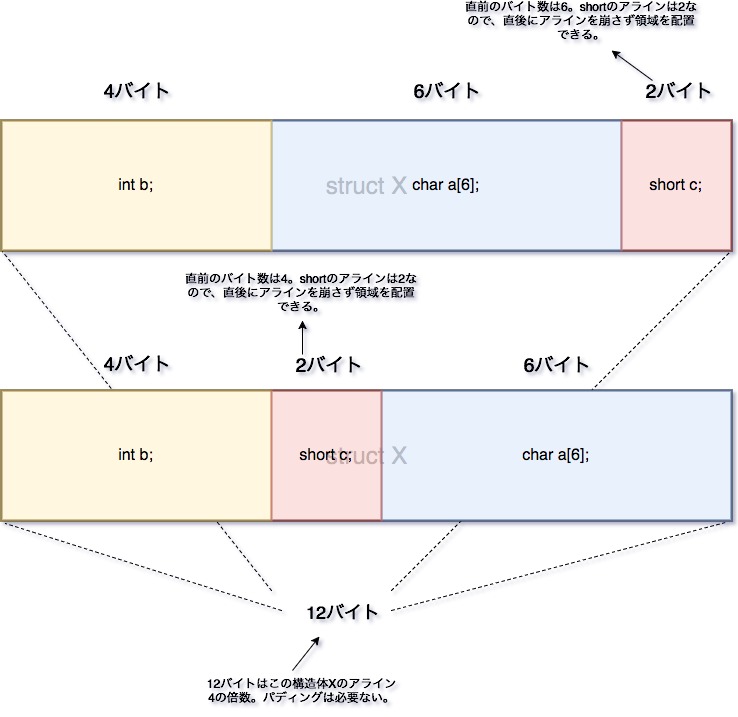
つまりこの問題は、char a[6]の末尾がintにとって都合の良いアドレスではないために起きる問題です。よって、無駄なパディングを発生させないためには、short型の前か、一番後ろに持ってきます。
struct X{
int b;
char a[6];
short c;
};
struct X{
int b;
short c;
char a[6];
};
再度サイズを見て見ましょう。
type: X
sizoef: 12
align: 4
どちらの場合も上記の結果になります。
shortのアライメントは2です。short cの直前のchar a[6]のバイトサイズは6です。6は2の倍数なので、char a[6]の直後にshort cの領域を詰めてしまってもアライメントが狂う事はありません。よって、パディングが発生しないのです。
このように、データ型それぞれのアライメントを把握してデータメンバを宣言する事は、余計なパディングを発生させないための良い慣習なのです。