16.5 評価の順序
評価順序について、まず深く触れる事となったのは第14章 マルチスレッドにてでした。しかし、実はこの評価順序に対する懸念は、マルチスレッドに限られた話ではないのです。一般的なシングルスレッドプログラミングの次元においても、式内の評価順序をどのように定めるべきか理解する必要があるのです。本章では、これを明らかにしていきます。ではまず本章で説明する、評価順序が考慮されるべき例を以下に示します。
int i;
i = 0;
i = ++i + 1; // A
i = i++ + 1; // B
i には A と B それぞれどのような値が代入されるでしょうか。その答えは、それぞれ C++ のバージョンによって異なります。このような差がなぜあるかというと、各バージョンごとに式の評価順序に対する解釈が全く異なるからです。本書はプログラミング未経験から C++17 に入門するドキュメントですが、それ以前の C++ コードを扱う上で混乱しないように、C++17 以前の範囲も含めてこの式の評価順序について説明していきます。
16.5.1 言語バージョンごとの解釈
前述した通り、式の評価順は、言語バージョンごとによって異なるため、それぞれを分けて説明します。その前に、まず副作用(side effects)という言葉の定義について理解する必要があります。以下にその要点を示します。
volatileglvalue で指定されたオブジェクトを読み込む- オブジェクトを変更する
- ライブラリ入出力関数を呼び出す
- またはそれらの操作のいずれかを行う関数を呼び出す
平たく言えば、オブジェクトに対する変更操作を言います。これを踏まえて、言語バージョンごとの評価順序について理解していきましょう。
C++98/03
C++98/03 では、副作用完了点(sequence point)という概念が評価の規則を司っています。副作用完了点とは、副作用が決定される事を保証する地点(タイミング)を言います。具体的には、以下のようなものが挙げられます(イメージとして^マークで示しています)。
- セミコロン
;i = 42; // ^ - 関数の実引数の評価直後
f(i); - 関数の返却値のコピー直後
i = f(); - 論理和演算子
||または論理積演算子&&の左辺の評価直後i || j ; // ^ i && j ; // ^ - コンマ演算子
,の左辺の評価直後i , j ; // ^
int i;
i = 0;
// ^ 副作用完了点 (a
i = ++i + 1; // 未定義動作
// ^ 副作用完了点 (b
i = i++ + 1; // 未定義動作
// ^ 副作用完了点 (c
(a と (b の二つの副作用完了点の間に、i = ...と++iという副作用が二つ存在していますから該当式文は未定義動作となります。また、(b と (c の二つの副作用完了点間に、i = ...とi++という副作用が二つ存在していますからこちらの該当式文も未定義動作となります。
C++11/14
C++11/14 では、C++03 以前の評価基準とは異なるものとなっています。
用語
ここで、C++11/14 における評価順序を説明する前に前述した side effects に加えていくつかの用語を定義しておきます。
- value computation
value computation は、式が表している値を取り出す、つまり読み込み操作の事を言います。C++コミュニティでは、これをvcと略称する事があります。本章でもこれを vc と表記します。
- side effects
前述した通りです。尚 C++コミュニティでは、これをseと略称する事があります。本章でも以下これを se と表記します。
- 評価(evaluation)
vc と se をまとめて評価(evaluation)と言います。
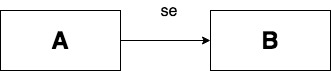
- sequenced-before
単一のスレッドにおける2つの変数アクセス間の順序/前後関係を示す用語です。例えば「A sequenced-before B」ならば、アクセス A は アクセス B より前に行われる事が保証されるという事を示します。(happens-before と同じではありません。happens-before は異なるスレッド間における順序付け関係を示します。)
- unsequenced
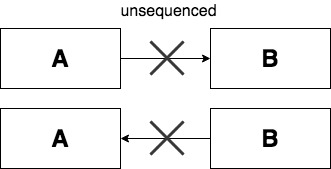
「A sequenced-before B」でも「B sequenced-before A」でもない事を「A と B は unsequenced」と言います。「A と B が unsequenced」である場合、A と B は任意の順序で実行され、重複する可能性があります(単一の実行スレッド内で、コンパイラは A 及び B を含むCPU命令をインターリーブする事ができます)。
- full-expression
full-expression とは、別の式の部分式ではない式を言います。
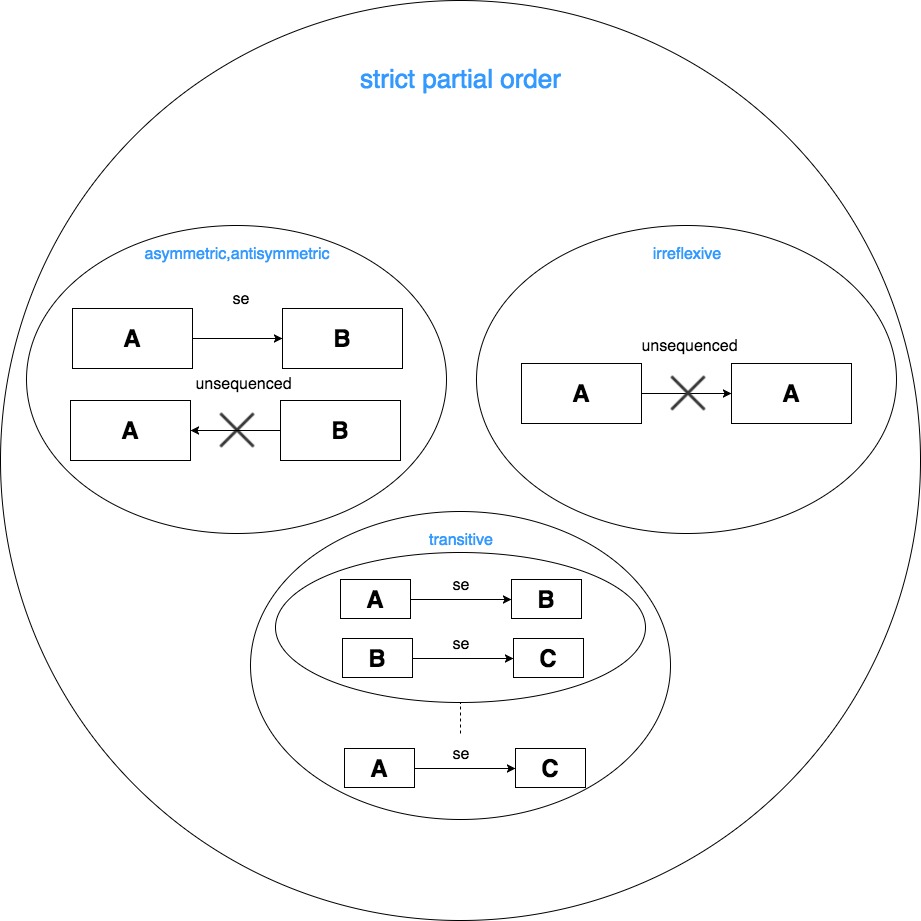
- 厳密な半順序(strict partial order)
sequenced-before 関係の性質を考えると、A は A 自身に対して sequenced-before ではありません。この性質を非反射的(irreflexive)と言います。また、「A sesequenced-before B」である場合、決して「B sequenced-before A」とはなりません。この性質を非対称的(asymmetric,antisymmetric)と言います。また、「A sequenced-before B」であり、かつ「B sequenced-before C」である場合、「A sequenced-before C」である事が保証されます。この性質を推移的(transitive)と言います。非反射的かつ非対称的かつ推移的である事を厳密な半順序(strict partial order)と言います。
C++11/14 の解釈
C++11/14は、前述した C++03 以前の副作用完了点という概念を廃止して、sequenced-before 関係によって評価順を規定します。つまり、C++11/14以降は、各部分式による evaluation の sequenced-before 関係が成立している場合のみその評価順序が保証され、unsequenced な se が存在する場合、未定義動作を引き起こす事になります。もう一度冒頭で述べたコードを掲載します。
int i;
i = 0; // A
i = ++i + 1; // B
i = i++ + 1; // C
まずは上記のコードAを vc と se を使って表現して見ましょう。
記号. 評価: 概要
というように示すと、以下のようになります。現時点では以下の並びと実際の順序は全く断定できるものではないため、無関係である事に注意してください。
a. vc: 0
b. se: i = 0
これについてsequenced-before 関係を見出していきます。
- 組み込みの代入演算子と組み込みのすべての複合代入演算子のse(左オペランドの変更)は、左と右のオペランドのvc の後に順序付けされ、代入式のvc の前に順序付けされます。
よって
- 定義#A: 「左辺vc sequenced-before 代入演算子se」
- 定義#B: 「右辺vc sequenced-before 代入演算子se」
が定義できます。先ほど示した a. と b. はこの定義に直接当てはめる事ができるので、iには必ず0が代入される事が保証されますね。

続いてコード B について考察していきます。まず、++iは、i += 1と等価ですから以下のように置き換える事ができます。
i = i += 1 + 1; // B
そして、それぞれの部分式に対して名付けます。
i = (i += 1) + 1;
// ~~~~~~ 部分式 X
// ~~~~~~~~~~~~ 部分式 Y
// ~~~~~~~~~~~~~~~~~~~ 式 Z
A と同様、各評価を示します。またA と同様、以下の並びには実際の順序と
a. vc: i 部分式X/左辺 i 読み込み
b. vc: 1 部分式X/右辺 1 読み込みと加算
c. se: i+=1 部分式X/左辺 i 変更
d. vc: 1 部分式Y/右辺 1 読み込み
e. vc: i+1 部分式Y/右辺 1 読み込みと加算
f. se: i 式Z 変更
これに対して sequenced-before 関係を見出していきます。
- 組み込みの前置インクリメント演算子と前置デクリメント演算子の se は、その vc の前に順序付けされます。
- 演算子のオペランドのvc は、演算子の結果のvc の前に順序付けされます
よって
- 定義#C: 「前置インクリメント演算子/デクリメント演算子se sequenced-before 前置インクリメント演算子/デクリメント演算子 vc」
- 定義#D: 「演算子のオペランドvc sequenced-before 演算子の結果のvc」
が定義できます。コード B は #A, #B, #C, #Dの定義を用いて順序付けする事ができます。#A かつ #B かつ #C かつ #D により、transitive となるため同一オブジェクトへの se 間が unsequesed ではないため、well-defined となります。
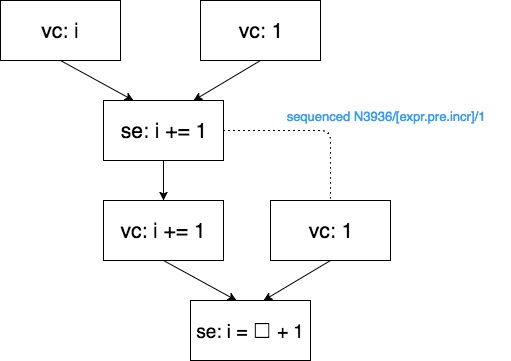
C++98/03 ではコード B は未定義動作を引き起こしましたが、C++11/14 でコード B は確実に2となる事が保証されました。
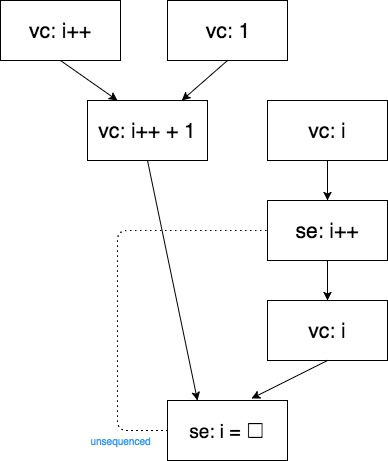
次にコード C について考えて見ましょう。コード C で懸念しなければならない点は、インクリメントが後置である事です。
i = i++ + 1; // C
- 後置インクリメントvc は、se の前に順序付けされます
よって
- 定義#E: 「後置インクリメント/デクリメントvc sequenced-before 後置インクリメント/デクリメントse」
が定義できます。コード C は#A,#B,#D,#E の定義を用いて順序付ける事になります。しかし、#A と #E の定義間には sequenced-before 関係がありまん。よって該当部分が unsequesed となります。unsequesed となっている評価は se なので、未定義動作を引き起こす事となります。
C++17
最後に、C++17 での解釈を考察していきます。
C++17 では前述した C++11/14 の規定に加えて、以下の規定が追加されました。
- すべての簡単な代入式
E1 = E2とすべての複合代入式E1 @ = E2(@は任意の複合代入演算子の意)では、E1のすべての vc と seの前に、E2のすべての vc と se が順序付けられます。
よって
- 定義#F: 「E2 sequenced-before E1」すなわち「後置インクリメントse sequenced-before 代入演算子se」
が定義できます。まず、コード A と コード B は、C++11/14 と同様に、順序が保証されています。コードは C は定義 #D により、同一オブジェクトへのアクセス間に sequenced-before 関係が成り立つため、iは必ず2となる事が保証されます。
コード C はC++11/14 以前では未定義動作を引き起こしましたが、C++17 以降はその動作が保証されます。
C++17 でも unsequenced である場合はどのようなコードでしょうか。例えば、以下のようなものが考えられますね。
i = ++i + i++;
これは以下と同義です。
i = i += 1 + i++;
定義#Dによって、代入式における左オペランドと右オペランドの sequenced-before 関係は確率されましたが、同じ辺内における se i+=1と se i++i の vc 及び se の sequenced-before 成立せず、unsequenced となります。よって、コード D は未定義動作を引き起こします。