9.4 演算子のオーバーロード
第6章で、関数をオーバーロードできる事を学びましたが、なんと演算子すらもオーバーロードを行う事ができるのです。演算子のオーバーロードを適切に活用する事で、ソースコードに高いセマンティックを与える事ができます。順に学んでいきましょう。
9.4.1 二項算術演算子のオーバーロード
まずは最も単純な、+演算子からオーバーロードを行なっていきます。+演算子は、通常加算を表す演算子ですね。演算子のオーバーロードはクラス内でも、グローバル領域でも行う事が可能です。
まずは、クラス内で+演算子を定義してみましょう。
#include<iostream>
struct X{
constexpr X(int a,int b):a_(std::move(a)),b_(std::move(b)){}
void print()const{std::cout<<"a: "<<a_<<"\nb: "<<b_<<std::endl;}
X operator+(const X& other)const
{
return X(a_+other.a_,b_+other.b_);
}
private:
int a_,b_;
};
int main()
{
X x1(10,20),x2(30,40);
X x3=x1+x2; // X::operator+を使用
x3.print();
}
実行結果は以下の通りです。
a: 40
b: 60
このように、オーバーロードしたい演算子の手前にoperatorというキーワードを付与する必要があります。単に、X& +(const X&) ....というようには書けません。この理由は、単にコンパイラの構文解析を容易にするためです。
さて、このコードの中で少し疑問に思える点があるかもしれません。
例えば、オーバーロードされたoperator+の引数が、一つである点です。+演算子は上記コードでもあるように、二つの引数があってそれらの加算結果を戻すはずですが、受け取る引数は一つとなっています。
何故この記述で正しく動作するのかは、メンバ関数の動作を思い出せば容易に理解できるはずです。全てのstaticでないメンバ関数は、呼び出し時にthisポインターが暗黙的に渡されると前述しました。thisポインターは自身のメンバーを指し示しますので、引数が二つなくとも、自身のメンバーに正しくアクセスする事ができるのです。よって、引数は1つだけで済みます。
尚、今までのメンバ関数と同じような様々な修飾や指定が可能です。以下は一例です。
#include<iostream>
struct X{
constexpr X(int a,int b):a_(std::move(a)),b_(std::move(b)){}
void print()const{std::cout<<"a: "<<a_<<"\nb: "<<b_<<std::endl;}
X operator+(const X& other)const & // lvalue修飾
{
std::cout<<"lvalue plus"<<std::endl;
return X(a_+other.a_,b_+other.b_);
}
X operator+(const X& other)const && // rvalue修飾
{
std::cout<<"rvalue plus"<<std::endl;
return X(a_+other.a_,b_+other.b_);
}
private:
int a_,b_;
};
int main()
{
X x1(10,20),x2(30,40);
X x3=x1+x2; // lvalue版のX::operator+を呼び出す
x3.print();
X x4=X(10,20)+x2; // rvalue版のX::operator+を呼び出す
x4.print();
}
実行結果は以下の通りです。
lvalue plus
a: 40
b: 60
rvalue plus
a: 40
b: 60
ここまで見てきてお気づきになったかもしれませんが、演算子のオーバーロードは、完全にプログラマ側によって演算子の意味を変えてしまう事ができます。よって、例えば極端な例で言えば、加算を表すoperator+の動作を、減算にしてしまう事だって出来てしまうのです。
#include<iostream>
struct X{
X(int a,int b):a_(std::move(a)),b_(std::move(b)){}
void print()const
{
std::cout<<"a: "<<a_<<"\nb: "<<b_<<std::endl;
}
X operator+(const X& other)const
{
return X(a_-other.a_,b_-other.b_); // operator+の実際の処理が減算...
}
private:
int a_,b_;
};
int main()
{
X x1(10,20),x2(30,40);
X x3=x2+x1;
x3.print();
}
実行結果は以下の通りです。
a: 20
b: 20
しかし、このような本質的な意味を損なうオーバーロードは、ただ厄介になるだけです。後々自分が困りたくないのであれば、このような事はしない方が身のためでしょう。減算がしたいのであれば、-演算子をオーバーロードすれば良いだけです。
#include<iostream>
struct X{
X(int a,int b):a_(std::move(a)),b_(std::move(b)){}
void print()const
{
std::cout<<"a: "<<a_<<"\nb: "<<b_<<std::endl;
}
X operator-(const X& other)const
{
return X(a_-other.a_,b_-other.b_);
}
private:
int a_,b_;
};
int main()
{
X x1(10,20),x2(30,40);
X x3=x2-x1;
x3.print();
}
実行結果は以下の通りです。
a: 20
b: 20
乗算や除算、剰余算も同じように実装しましょう。
#include<iostream>
struct X{
constexpr X(int a,int b):a_(std::move(a)),b_(std::move(b)){}
void print()const
{
std::cout<<"a: "<<a_<<"\nb: "<<b_<<std::endl;
}
constexpr X operator+(const X& other)const noexcept
{
return X(a_+other.a_,b_+other.b_);
}
constexpr X operator-(const X& other)const noexcept
{
return X(a_-other.a_,b_-other.b_);
}
constexpr X operator*(const X& other)const noexcept
{
return X(a_*other.a_,b_*other.b_);
}
constexpr X operator/(const X& other)const noexcept(false)
{
return X(a_/other.a_,b_/other.b_);
}
constexpr X operator%(const X& other)const noexcept(false)
{
return X(a_%other.a_,b_%other.b_);
}
private:
int a_,b_;
};
int main()
{
X x1(10,20),x2(30,40);
(x1+x2).print();
(x2-x1).print();
(x1+x2).print();
(x2/x1).print();
(x2%x1).print();
}
実行結果は以下の通りです。
a: 40
b: 60
a: 20
b: 20
a: 40
b: 60
a: 3
b: 2
a: 0
b: 0
除算のみ例外指定がnoexcept(false)となっており、例外を送出する可能性がある事を明記していますが、その理由は0除算が起こり得るためです。0除算が発生した場合、例外を送出する可能性があります(実装依存)。
ところで、以上の算術演算子は、フレンド指定を行なった非メンバ関数として定義する事もできます。
#include<iostream>
struct X{
constexpr X(int a,int b):a_(std::move(a)),b_(std::move(b)){}
void print()const
{
std::cout<<"a: "<<a_<<"\nb: "<<b_<<std::endl;
}
private:
int a_,b_;
friend constexpr X operator+(const X& l,const X& r)noexcept
{
return X(l.a_+r.a_,l.b_+r.b_);
}
friend constexpr X operator-(const X& l,const X& r)noexcept
{
return X(l.a_-r.a_,l.b_-r.b_);
}
friend constexpr X operator*(const X& l,const X& r)noexcept
{
return X(l.a_*r.a_,l.b_*r.b_);
}
friend constexpr X operator/(const X& l,const X& r)noexcept(false)
{
return X(l.a_/r.a_,l.b_/r.b_);
}
friend constexpr X operator%(const X& l,const X& r)noexcept(false)
{
return X(l.a_%r.a_,l.b_%r.b_);
}
};
int main()
{
X x1(10,20),x2(30,40);
(x1+x2).print();
(x2-x1).print();
(x1+x2).print();
(x2/x1).print();
(x2%x1).print();
}
実行結果は前述した結果と同様です。フレンド関数の項で、クラス内にフレンド関数を定義した場合はADLでのみ呼び出す事ができると前述しましたが、演算子のオーバーロードにとってはまさに持って来いの機能です。グローバル空間からこれらの関数を呼び出す事はできないので、グローバル名前空間の汚染の防止に役立ちます。
フレンド関数版の方では、引数が二つになっている事にお気づきになったかと思いますが、これはこの関数自体はメンバ関数ではなく、通常の関数であるため、thisポインタが渡される事もありません。よって、引数には自分自身の型のオブジェクトを二つ受け取るようにします。
さて、フレンド関数は、二項演算子のオーバーロードにおいて、メンバ関数にてオーバーロードするよりも有効的であるシーンが多いです。例えば、以下のようなクラスがあったとします。
struct X{
constexpr X(int a):a_(std::move(a)){}
void print(){std::cout<<a_<<std::endl;}
private:
int a_;
};
このクラスに対して、演算子のオーバーロードを用いて、Xクラス同士の加算とint型の値を受け取る加算をサポートしたいとします。この時、メンバ関数として二項算術演算子を定義してみます。
#include<iostream>
struct X{
constexpr X(int a):a_(std::move(a)){}
void print(){std::cout<<a_<<std::endl;}
constexpr X operator+(const X& other)noexcept
{
return X(a_+other.a_);
}
constexpr X operator-(const X& other)noexcept
{
return X(a_-other.a_);
}
constexpr X operator*(const X& other)noexcept
{
return X(a_*other.a_);
}
constexpr X operator/(const X& other)noexcept(false)
{
return X(a_/other.a_);
}
constexpr X operator%(const X& other)noexcept(false)
{
return X(a_%other.a_);
}
constexpr X operator+(int other)noexcept
{
return X(a_+other);
}
constexpr X operator-(int other)noexcept
{
return X(a_-other);
}
constexpr X operator*(int other)noexcept
{
return X(a_*other);
}
constexpr X operator/(int other)noexcept(false)
{
return X(a_/other);
}
constexpr X operator%(int other)noexcept(false)
{
return X(a_%other);
}
private:
int a_;
};
int main()
{
X x1=10,x2=20;
(x1+x2).print();
(x2-x1).print();
(x1*x2).print();
(x2/x1).print();
(x2%x1).print();
(x1+10).print();
(x1-10).print();
(x1*10).print();
(x2/10).print();
(x2%10).print();
}
実行結果は以下となります。
30
10
200
2
0
20
0
100
2
0
正しく実行できました。しかし、この実装は、ある一部の式の記述方式をサポートできていません。以下のように記述した場合、コンパイルは通らないのです。
// Xの定義...
int main()
{
X x1=10,x2=20;
(10+x1).print(); // 左辺にint型の値を受け付ける事ができない
(10-x1).print();
(10*x1).print();
(10/x1).print();
}
考えてみれば当然な事が分かると思います。メンバ関数版の二項演算子のオーバーロードでは、左辺は自分自身の型のみと決まっているので、int型の値を受け取る事はできないのです。
これを解決するには、オーバーロードした演算子をフレンド関数にします。
#include<iostream>
struct X{
constexpr X(int a):a_(std::move(a)){}
void print(){std::cout<<a_<<std::endl;}
constexpr X operator+(const X& other)noexcept
{
return X(a_+other.a_);
}
constexpr X operator-(const X& other)noexcept
{
return X(a_-other.a_);
}
constexpr X operator*(const X& other)noexcept
{
return X(a_*other.a_);
}
constexpr X operator/(const X& other)noexcept(false)
{
return X(a_/other.a_);
}
constexpr X operator%(const X& other)noexcept
{
return X(a_%other.a_);
}
constexpr X operator+(int other)noexcept
{
return X(a_+other);
}
constexpr X operator-(int other)noexcept
{
return X(a_-other);
}
constexpr X operator*(int other)noexcept
{
return X(a_*other);
}
constexpr X operator/(int other)noexcept(false)
{
return X(a_/other);
}
constexpr X operator%(int other)noexcept(false)
{
return X(a_%other);
}
private:
int a_;
friend constexpr X operator+(int l,const X& r)noexcept
{
return X(l+r.a_);
}
friend constexpr X operator-(int l,const X& r)noexcept
{
return X(l-r.a_);
}
friend constexpr X operator*(int l,const X& r)noexcept
{
return X(l*r.a_);
}
friend constexpr X operator/(int l,const X& r)noexcept(false)
{
return X(l/r.a_);
}
friend constexpr X operator%(int l,const X& r)noexcept(false)
{
return X(l%r.a_);
}
};
int main()
{
X x1=10;
(10+x1).print();
(10-x1).print();
(10*x1).print();
(10/x1).print();
(10%x1).print();
}
実行結果は以下の通りです。
20
0
100
1
0
このように、二項算術演算子に対してオーバーロードする際に自身の型以外のオブジェクトを受け取りたい場合は、必ずフレンド指定された非メンバ関数版の演算子オーバーロードを記述するべきとなりますので、一括して管理するために、全ての二項演算子のオーバーロードをフレンド指定された非メンバ関数で定義する事が多いです。
9.4.2 メンバ選択演算子のオーバーロード
メンバ選択演算子は.と->がありますが、C++17では.演算子をオーバロードする事ができないため、メンバ選択演算子と言われたら->の事を示します。当演算子をオーバーロードする事で独自に定義したクラスに対して->を用いる事ができるようになります。まずはコードを見ていただきましょう。
#include<iostream>
struct X{
constexpr explicit X(int a):a_(std::move(a)){}
void print()const{std::cout<<a_<<std::endl;}
private:
int a_;
};
struct unique_smart_ptr{
unique_smart_ptr():ptr(nullptr){}
unique_smart_ptr(X* x):ptr(x){}
unique_smart_ptr(unique_smart_ptr&& other)noexcept:ptr(other.ptr)
{
other.ptr=nullptr;
}
unique_smart_ptr(const unique_smart_ptr&)=delete;
unique_smart_ptr& operator=(const unique_smart_ptr&)=delete;
X* operator->()const noexcept{return ptr;} // メンバ選択演算子のオーバーロード
~unique_smart_ptr()noexcept{if(ptr)delete ptr;}
private:
X* ptr;
};
int main()
{
unique_smart_ptr x(new X(42));
x->print();
}
実行結果は以下の通りです。
42
少し複雑なコードに見えるかもしれませんが、実際の仕組みを理解できればそれほど難しい事をしているわけではないように思えるはずです。
クラス、unique_smart_ptrは、ヒープ領域へのポインタを簡易的にシミュレートしたクラスです。ヒープ領域を指すポインタを利用する上での一つの注意点として、使わなくなった段階でdeleteを明示的に行わなければデータの解放が行われないという点があります。スマートポインタは、この弱点を克服するための一つの方法です。スマートポインタの更に詳しい概念については後の第12章「STLと標準ライブラリ」にて詳しく取り上げます。今は、このunique_smart_ptrというクラスはヒープ領域へのデータ破棄を自動的に行なってくれるポインタのシミュレータなんだな程度の理解で構いません。
さて、クラスはまあ良いとして、メンバ選択演算子の話に戻りましょう。オーバーロードは上記のように、内部で確保しているポインターを返します。->演算子のオーバーロードでは引数はありません。また、その性質上、前述した算術演算子のように非メンバ関数として定義する事はできません。処理としては->を用いてクラスXは内部に持つprintという関数を呼び出します。つまり、これは以下のと全く同じ意味になるという事です。
x.operator->()->print();
この動作は、上記のクラスunique_smart_ptrを使わずに単純に、Xの一つのインスタンスをヒープ上に確保してそれをポイントすれば分かりやすいでしょう。
X* x=new X(42);
x->print();
delete x;
ポインタを利用してそのポイント先の内部のデータメンバを呼び出す場合、->演算子を使いますよね。unique_smart_ptrはポインターのシミュレータなので、これと同じように動く必要がありますから、上記のようにオーバーロードしました。
さて、その他の処理はメンバ選択演算子とは直接的に関係がなく、リソースの管理面で必要な記述が書かれています。これについては前述下通り、第12章にて詳しく説明します。
9.4.3 添え字演算子のオーバーロード
添え字演算子[]をオーバーロードする事もできます。まずは、以下のコードを見てください。
#include<iostream>
struct X{
X():ar{}
{
for(int& i:ar)i=42;
}
const int& operator[](const std::size_t x)const& noexcept{return ar[x];} // 添え字演算子のオーバーロード
int& operator[](const std::size_t x)&{return ar[x];} // これも
int operator[](const std::size_t x)&&{return ar[x];} // そしてこれも
constexpr std::size_t size()const noexcept{return sizeof(ar)/sizeof(ar[0]);}
private:
int ar[5];
};
int main()
{
X x;
for(unsigned int i=0; i<x.size(); ++i)std::cout<<x[i]<<std::endl;
}
実行結果は以下の通りです。
42
42
42
42
42
クラスXは、固定長5の配列の簡易的なシミュレータであると考えると分かりやすいかもしれません。[]演算子はメンバ関数でなければなりません。上記のコードでは三つに[]演算子をオーバーロードしています。全てに共通しているのは、内部のメンバ、arのインデックスアクセスを行なっているという点です。[]演算子は、通常の配列のように使う事を考えた時、インデックスアクセスの処理が起きる事を想定しますから、このようにオーバーロードしました。三つにオーバーロードしている理由は、オーバーロードされている各種の修飾部分などを見ていただければ分かるように、対象のオブジェクトがlvalueかrvalueか、またconstかconstでないかです。constなオブジェクトに対しては、インデックスアクセスも当然constなアクセスでなければなりませんからconst修飾を付与し、戻り値も、そこから変更できないようにconstを設定します。constでないオブジェクトに対しては、インデックスアクセスからその要素への変更操作を行う可能性がありますから、内部メンバの指定要素の参照を返す事で実現します。rvalueなオブジェクトからのインデックスアクセスは、その性質上即座に破棄される可能性があるので、指定インデックスの参照を返してしまった場合、破棄済みの領域に対する参照を渡す事となってしまい、不正アクセスになってしまいますから、その要素の値をコピーして返します。
動作としては、単純ですね。コンストラクタで内部メンバのarの全ての要素に42を代入していますから、X xのタイミングでそれが適用されます。その後のfor文では先ほどオーバーロードした添え字演算子を用いて全ての要素を出力させています。その際、sizeというようなメンバ関数を内部で定義しておいたので、これを利用しています。sizeというメンバ関数は、単にメンバarのサイズを返すだけのメンバ関数ですが、このようにしておく事で、サイズを直接打ち込む場合よりも、範囲オーバーなアクセスを予防する事ができます。
9.4.4 関数呼び出し演算子のオーバーロード/関数オブジェクト
関数呼び出し演算子()もオーバーロードする事ができます。以下のコードを見てください。
#include<iostream>
struct X{
void operator()()const{std::cout<<__func__<<std::endl;} // 関数呼び出し演算子のオーバーロード
};
int main()
{
X x;
x();
}
実行結果は以下の通りです。
operator()
x()は、一見すると不思議な記述に見えますが、これは関数呼び出し演算子のオーバーロードによって実現しています。関数呼び出し演算子はメンバ関数でなければなりません。関数呼び出し演算子のオーバーロードは、そのオーバーロードされた型のインスタンスから関数呼び出しの記述法によってoperator()()内部の処理を実行するために用意された機能であり、それ以外の何の意味もありません。しかし、これはどのようなシーンで使えるのでしょうか。これは、例えば以下のように使えます。
#include<iostream>
struct equal{
constexpr bool operator()(int x,int y)const noexcept{return x==y;}
};
void compare(const int x,const int y,const equal& functor)
{
std::cout<<"functor is "<<std::boolalpha<<functor(x,y)<<std::endl;
}
int main()
{
compare(10,20,equal());
compare(10,10,equal());
}
実行結果は以下の通りです。
functor is false
functor is true
compare関数に対してequalのインスタンスを渡しています。その内部ではその受け取ったインスタンスのoperator()を呼び出しその内部の動作によって実行結果が変動するようにしてあります。つまり、クラスequalの内部のoperator()内の定義によって、compare内で実行される内容を変える事ができるのです。例えばクラスequalのoperator()内部を以下のように変更した場合
struct equal{
constexpr bool operator()(int x,int y)const noexcept{return x!=y;}
};
xとyの両者の値が等しくない場合という条件を作る事ができるという事です。このように変更した場合、出力結果は以下のようになるでしょう。
functor is true
functor is false
これは、どこかで同じような事をした覚えはないでしょうか。そうです、関数ポインタによって同じような事をしたのです。
#include<iostream>
bool equal(int x,int y)noexcept{return x==y;}
void compare(const int x,const int y,bool (*const f_ptr)(int,int))
{
std::cout<<"functor is "<<std::boolalpha<<f_ptr(x,y)<<std::endl;
}
int main()
{
compare(10,20,equal);
compare(10,10,equal);
}
実行結果は以下となります。
functor is false
functor is true
機能としては、何ら代わりはありません。しかし、関数を定義して関数ポインタを渡すよりもこのようにして関数呼び出し演算子をオーバーロードした型を渡した方が有用的/直感的となるシーンが多くあるのです。これについては、テンプレートという概念を学習する際に明らかとなるでしょう。 尚、このように、関数呼び出し演算子がオーバーロードされたクラスのインスタンスを関数オブジェクトと言います。また、関数オブジェクトはその性質上、引数の数は自由です。
9.4.5 インクリメント/デクリメント演算子のオーバーロード
インクリメント++、デクリメント--演算子もオーバーロードする事ができます。まずは以下のコードを見て見ましょう。
#include<iostream>
struct X{
constexpr X(int a):a_(std::move(a)){}
X& operator++()noexcept // 前置インクリメント演算子のオーバーロード
{
++a_;
return *this;
}
X operator++(int)noexcept // 後置インクリメント演算子のオーバーロード
{
X tmp=*this;
++a_;
return tmp;
}
X& operator--()noexcept // 前置デクリメント演算子のオーバーロード
{
--a_;
return *this;
}
X operator--(int)noexcept // 後置デクリメント演算子のオーバーロード
{
X tmp=*this;
--a_;
return tmp;
}
void print()const{std::cout<<a_<<std::endl;}
private:
int a_;
};
int main()
{
X x(42);
(++x).print();
(x++).print();
(--x).print();
(x--).print();
}
実行結果は以下となります。
43
43
43
43
インクリメント/デクリメントには、前置と後置の記述法がある事を思い出してください。それぞれ、前置は
X& operator++();
X& operator--();
後置は
X operator++(int);
X operator--(int);
によってオーバーロードしています。前置はとても直感的ですね。単に内部のメンバをインクリメントして、自身を返しています。後置は、その性質上、インクリメント/デクリメントを行なった直後の評価では、インクリメント/デクリメントの結果が反映される前の値を返す必要があります。よって、一時的に内部でオブジェクトを保存しておいてからインクリメント/デクリメントを適用し、適用される前のオブジェクトを返す事で実現しているのです。後置のインクリメント/デクリメントの返却型が参照ではない事に注意してください。ここで参照を返してしまうと、tmpという内部オブジェクトの参照を返す事となり、関数の終了後にはtmp破棄されてしまうので、その破棄された参照を返す事となり、これを使うと不正アクセスとなってしまうため、参照ではなく、コピーを返す必要があります。また、インクリメント/デクリメント演算子のオーバーロードは非メンバ関数としても行う事ができますが、殆どの場合メンバ関数として定義します。
#include<iostream>
struct X{
constexpr X():a(0){}
void print()const{std::cout<<a<<std::endl;}
int a;
};
X& operator++(X& x)noexcept // 前置
{
++x.a;
return x;
}
X operator++(X& x,int)noexcept // 後置
{
X tmp=x;
++x.a;
return tmp;
}
int main()
{
X x;
X a=++x;
a.print();
X b=x++;
b.print();
}
9.4.6 シフト演算子
シフト演算子<<もオーバーロードする事ができます。まずは以下のコードを見てください。
#include<iostream>
#include<bitset>
#include<limits>
struct X{
constexpr X(unsigned char x=0):data_(std::move(x)){}
X operator<<(std::size_t n)const noexcept
{
X tmp=*this;
tmp.data_<<=n;
return tmp;
}
X operator>>(std::size_t n)const noexcept
{
X tmp=*this;
tmp.data_>>=n;
return tmp;
}
unsigned char data_;
};
int main()
{
X x=std::numeric_limits<unsigned char>::max();
X result1=x<<1;
X result2=x>>1;
std::cout<<std::bitset<CHAR_BIT>(result1.data_)<<std::endl;
std::cout<<std::bitset<CHAR_BIT>(result2.data_)<<std::endl;
}
実行結果は以下の通りです。
11111110
01111111
上記のように、単純にビット演算のセマンティックを表すように実装します。尚、シフト演算子のオーバーロードとは特に関係はありませんが、std::numeric_limits<unsigned char>::max()は、unsigned charが格納できる最大値を表します。また、CHAR_BITはchar型が何ビットであるかを表します。シフト演算子は非メンバ関数として定義する事もできます。
#include<iostream>
#include<bitset>
#include<limits>
struct X{
constexpr X(unsigned char x=0):data_(std::move(x)){}
unsigned char data_;
friend X operator<<(const X& x,std::size_t n)noexcept
{
X tmp=x;
tmp.data_<<=n;
return tmp;
}
friend X operator>>(const X& x,std::size_t n)noexcept
{
X tmp=x;
tmp.data_>>=n;
return tmp;
}
};
int main()
{
X x=std::numeric_limits<unsigned char>::max();
X result1=x<<1;
X result2=x>>1;
std::cout<<std::bitset<CHAR_BIT>(result1.data_)<<std::endl;
std::cout<<std::bitset<CHAR_BIT>(result2.data_)<<std::endl;
}
実行結果は先ほどを変わりません。実際は、シフト演算子を定義する際は非メンバ関数として定義する事の方が多いです。因みにこれは余談ですが、標準出力オブジェクト、std::coutは、このシフト演算子の本来の意味を無視して標準出力に出力させるといった動作を実装しています(本来は、演算子のそのものの意味を無視してオーバーロードするのは好ましくありません)。つまり、例えば自身の作ったオリジナルの型を<<を用いてstd::coutに流したい場合、独自に<<演算子をオーバーロードする事で実現できます。std::coutはstd::ostreamのオブジェクトなので、引数にはstd::ostreamを受け付けるようにしてあげれば良いことになります。
#include<iostream>
struct X{ // オリジナルの型
constexpr X(int x=0):x_(std::move(x)){}
private:
int x_;
friend std::ostream& operator<<(std::ostream& os,const X& x) // std::coutはstd::ostream型なのでstd::ostream型で、またストリームの内容を変更するため、参照で受け取る。
{
return os<<x.x_;
}
};
int main()
{
X x=42;
std::cout<<x<<std::endl; // 上記のoperator<<が呼び出される
}
実行結果は以下の通りです。
42
9.4.7 ビット演算子
ビット演算し(&、^、|)もオーバーロードをすることができます。まずは以下のコードを見てください。
#include<iostream>
#include<bitset>
#include<limits>
struct X{
constexpr X(unsigned char x=0):data_(std::move(x)){}
X operator&(const X& other)const noexcept
{
return X(data_&other.data_);
}
X operator^(const X& other)const noexcept
{
return X(data_^other.data_);
}
X operator|(const X& other)const noexcept
{
return X(data_|other.data_);
}
private:
friend std::ostream& operator<<(std::ostream& os,const X& x)
{
return os<<std::bitset<CHAR_BIT>(x.data_);
}
unsigned char data_;
};
int main()
{
X x1=std::numeric_limits<unsigned char>::max(),x2=std::numeric_limits<unsigned char>::max()<<CHAR_BIT/2;
X result1=x1&x2;
X result2=x1^x2;
X result3=x1|x2;
std::cout<<result1<<std::endl;
std::cout<<result2<<std::endl;
std::cout<<result3<<std::endl;
}
実行結果は以下の通りです。
11110000
00001111
11111111
単純に、それぞれの演算子に期待される動作を実装します。ビット演算子は非メンバ関数としても定義することができます。大抵の場合、アドレス取得演算子と競合してしまう可能性も踏まえて非メンバ関数として定義する事が望ましいでしょう。
#include<iostream>
#include<bitset>
#include<limits>
struct X{
constexpr X(unsigned char x=0):data_(std::move(x)){}
private:
friend X operator&(const X& l,const X& r)noexcept
{
return X(l.data_&r.data_);
}
friend X operator^(const X& l,const X& r)noexcept
{
return X(l.data_^r.data_);
}
friend X operator|(const X& l,const X& r)noexcept
{
return X(l.data_|r.data_);
}
friend std::ostream& operator<<(std::ostream& os,const X& x)
{
return os<<std::bitset<CHAR_BIT>(x.data_);
}
unsigned char data_;
};
int main()
{
X x1=std::numeric_limits<unsigned char>::max(),x2=std::numeric_limits<unsgined char>::max()<<CHAR_BIT/2;
X result1=x1&x2;
X result2=x1^x2;
X result3=x1|x2;
std::cout<<result1<<std::endl;
std::cout<<result2<<std::endl;
std::cout<<result3<<std::endl;
}
実行結果は先ほどと変わりません。尚、&と^は、|と~が定義されていれば、それらを用いてその動作を定義する事が可能です。
#include<iostream>
#include<bitset>
#include<limits>
struct X{
constexpr X(unsigned char x=0):data_(std::move(x)){}
constexpr X operator~()const noexcept
{
return X(~data_);
}
private:
friend constexpr X operator|(const X& l,const X& r)noexcept
{
return X(l.data_|r.data_);
}
friend constexpr X operator&(const X& l,const X& r)noexcept
{
return ~(~l|r); // ~と|を利用して実装
}
friend constexpr X operator^(const X& l,const X& r)noexcept
{
return (l&~r)|(~l)&r; // ~と|と&を利用して実装
}
friend std::ostream& operator<<(std::ostream& os,const X& x)
{
return os<<std::bitset<CHAR_BIT>(x.data_);
}
unsigned char data_;
};
int main()
{
X x1=std::numeric_limits<unsigned char>::max(),x2=std::numeric_limits<unsigned char>::max()<<CHAR_BIT/2;
X result1=x1&x2;
X result2=x1^x2;
X result3=x1|x2;
std::cout<<result1<<std::endl;
std::cout<<result2<<std::endl;
std::cout<<result3<<std::endl;
}
実行結果は変わりません。
9.4.8 ビット否定演算子のオーバーロード
ビット否定演算子~もオーバーロードする事ができます。まずは以下のコードを見てください。
#include<iostream>
#include<bitset>
#include<limits>
struct X{
constexpr X(int x=0):data_(std::move(x)){}
X operator~()const // ビット否定演算子のオーバーロード
{
X tmp=*this;
tmp.data_=~data_;
return tmp;
}
int data_;
};
int main()
{
X x1(0^0);
std::cout<<static_cast<std::bitset<CHAR_BIT*sizeof(int)>>(x1.data_)<<std::endl;
X x2=~x1;
std::cout<<static_cast<std::bitset<CHAR_BIT*sizeof(int)>>(x2.data_)<<std::endl;
}
実行結果はCHAR_BITや、int型のビット数によってビット列の長さは異なりますが、筆者の環境では以下のようになりました。
00000000000000000000000000000000
11111111111111111111111111111111
環境によってビット列の長さは異なりますが、必ず全てのビットが反転します。ビット否定演算子のオーバーロードは、X operator~()constの部分で定義されています。この演算子は、非メンバ関数として定義する事が可能ですが、多くの場合メンバ関数であるべきです。
ビット否定演算子のオーバーロードでは、+、-、*、/、%などの演算子と同じように、演算子の適用元は値が変化してはなりませんので、まず自身を複製してそこにビット反転した値を格納し、複製したオブジェクトを返します。
9.4.9 キャスト演算子のオーバーロード
キャスト演算子って何だ?!と思うかもしれませんが、まずは以下のコードを見てください。
#include<iostream>
struct Integer{
constexpr Integer():x_(0){}
constexpr Integer(const int& x):x_(std::move(x)){}
constexpr Integer(const Integer&)=default;
constexpr Integer(Integer&&)=default;
constexpr Integer(int&& other):x_(std::move(other)){}
constexpr Integer& operator=(const Integer&)=default;
constexpr Integer& operator=(const int& other)
{
x_=other;
return *this;
}
constexpr Integer& operator=(Integer&&)=default;
constexpr Integer& operator=(int&& other)
{
x_=std::move(other);
return *this;
}
operator int()const noexcept // キャスト演算子のオーバーロード
{
return x_;
}
private:
int x_;
};
int main()
{
Integer a(42);
int b=a;
std::cout<<b<<std::endl;
}
実行結果は以下の通りです。
42
まず、クラスIntegerは簡易的に整数型をシミュレートしたクラスです。上記の通り、整数型をシミュレートするために、デフォルトコンストラクタからコピー、ムーブまで定義を揃えてあります。ここで一つ機能として欲しいのが、通常の整数型、例えばint型との互換性です。自身で作ったクラスIntegerの値をプリミティブな型のintに直接代入したいとします。そう言った場合、上記のようなキャスト演算子のオーバーロードを用います。シグネチャを見れば分かる通り、戻り型の記述は必要ありません。operatorの後に、自身の型から変換したい型を続けて記述します。上記の場合、int型に変換させるためにoperator int()というようになっています。その後のconstやnoexceptの記述があるように、通常のメンバ関数同様、これらのキーワードなどで修飾する事が可能です。inlineや、constexpr指定する事もできます。
struct Integer{
// ...
constexpr operator int() // constexpr指定されたキャスト演算子
{
// ...
}
};
また、キャスト演算子は、explicitを付与する事ができます。
struct Integer{
// ....
explicit operator int()
{
// ...
}
};
explicitを付与する事でどのような効果があるかというと、暗黙の型変換の防止です。例えば、上記のサンプルコードでは以下のようなコードもコンパイルが通ってしまいます。
struct Integer{
// 上記と同様 ...
operator int()const noexcept
{
return x_;
}
private:
int x_;
};
int main()
{
Integer a(42);
bool b=a; // bool型の初期値にできる
}
キャスト演算子で定義しているのはint型へのキャストのみですが、bool型にまで代入できてしまいました。これが、意図せぬ動作であるならばとても厄介な事となるでしょう。これは何が起きているのかというと、単純にキャスト演算子によって返されたint型の値が、bool型と暗黙変換が可能であるという面で互換性を持っているために起きてしまっているのです。このような暗黙変換を行わせないためには、explicitを付与します。
struct Integer{
// 上記と同様 ...
explicit operator int()const noexcept
{
return x_;
}
private:
int x_;
};
int main()
{
Integer a(42);
int b(a); // int型への初期化/代入/キャストはOK
bool c(a); // int型以外への初期化/代入/キャストはNG
}
explicitを付与する事で、意図せぬ暗黙変換を防止する事ができます。尚、上記のように、int型へのキャストであっても、例えば初期化する際には初期化側の記述として=を使う事ができなくなります。
int main()
{
Integer a(42);
int b=a; // NG. ()か{}ならOK
}
キャスト演算子は、非メンバ関数として定義する事はできません。
9.4.10 論理否定演算子のオーバーロード
論理否定演算子!もオーバーロードする事ができます。まずは以下のコードを見てください。
#include<iostream>
struct X{
constexpr X(int x=0):a(std::move(x)){}
constexpr explicit operator bool()const noexcept{return static_cast<bool>(a);}
constexpr bool operator!()const noexcept{return !static_cast<bool>(*this);} // 論理否定演算子のオーバーロード
int a;
};
int main()
{
X x;
std::cout<<std::boolalpha<<!static_cast<bool>(x)<<std::endl;
x=42;
std::cout<<!static_cast<bool>(x)<<std::endl;
}
実行結果は以下の通りです。
true
false
論理否定演算子のオーバーロードはconstexpr bool operator!()const noexceptの部分で行われています。内部では、自身をbool型に変換した値を返しています。しかし、その変換部分でエラーになるのでは?と思うかもしれませんが、その部分では論理否定演算子のオーバーロードが定義された上に記述されている、constexpr operator bool()が呼び出されます。ここで前述したbool型へのキャスト演算子が定義しているためエラーにはなりません。この論理否定演算子は上記のように、大抵は自身の型がbool型に変換可能な型で定義しなければ意味を成しません。。論理否定演算子は非メンバ関数として定義する事が可能ですが、大抵の場合メンバ関数として定義する事が望ましいです。
9.4.11 アドレス取得演算子のオーバーロード
アドレス取得演算子&もオーバーロードする事ができます。まずは以下のコードを見てください。
#include<iostream>
struct X{
X* operator&(){return this;} // アドレス取得演算子のオーバーロード
};
int main()
{
X x1;
X* address=&x1;
std::cout<<address<<std::endl;
}
単純に、自身のアドレスを返しています。と、ここまで言っておいてなのですが、アドレス取得演算子はオーバーロードすべきではないのです。何故ならば上記のように、アドレスを取得しようとした時、端的に自身のアドレスを返すというアドレス取得演算子そのものの意味が守られた動作を行うのであれば問題ありませんが、意図せず全く異なるアドレスを返せば、その動作は完全に期待の動作と異なってしまいます。また、例えばこの演算子をprivateメンバに宣言したりdelete指定したりしてしまったらアドレスを取得する事が不可能になってしまいます。しかし、逆を言えば、アドレスの取得を禁止したければそのように実装すれば良い事となります。ただ、それでもstd::addressofといったような関数を用いれば取得する事ができたりするので、実質的に無意味なのです。std::addressofについては、「STLと標準ライブラリ」の章で紹介しています。
尚、アドレス取得演算子は非メンバ関数として定義することもできますが、その場合ビット演算子とセマンティックが競合してしまうため、推奨されません。
9.4.12 関節参照演算子のオーバーロード
関節参照演算子*もオーバーロードする事ができます。乗算を表す*との違いは、二項演算子であるか単項演算子であるかで判別する事ができます。
#include<iostream>
struct X{
constexpr X(int a):a_(std::move(a)){}
void print()const{std::cout<<a_<<std::endl;}
private:
int a_;
};
struct unique_smart_ptr{
unique_smart_ptr():ptr(nullptr){}
unique_smart_ptr(X* x):ptr(x){}
unique_smart_ptr(unique_smart_ptr&& other)noexcept:ptr(other.ptr)
{
other.ptr=nullptr;
}
unique_smart_ptr(const unique_smart_ptr&)=delete;
unique_smart_ptr& operator=(const unique_smart_ptr&)=delete;
~unique_smart_ptr()noexcept{if(ptr)delete ptr;}
X& operator*()const noexcept{return *ptr;} // 関節参照演算子のオーバーロード
X& operator*(){return *ptr;} // 関節参照演算子のオーバーロード
private:
X* ptr;
};
int main()
{
unique_smart_ptr x(new X(42));
(*x).print();
}
実行結果は以下の通りです。
42
関節参照演算子のオーバーロードでもアロー演算子の時と同じように、簡易的にポインタをシミュレートしたクラスunique_smart_ptrを例として使います。通常ポインタには*演算子を使う事ができますね。その動作は、ポイント先の値を関節参照します。上記のオーバーロードでは、この動作をシミュレートしています。関節参照演算子は非メンバ関数として定義する事はできますが、用途としては推奨されないでしょう。
#include<iostream>
struct X{
void f(){std::cout<<__func__<<std::endl;}
};
void operator*(X& x)
{
x.f();
}
int main()
{
X x;
*x;
}
9.4.13 Pointer to Member演算子
Pointer to Member演算子とは->*の事です。まず、->*をどのようなシーンで使うのか思い出しましょう。
#include<iostream>
struct X{
void f(){std::cout<<__func__<<std::endl;};
};
int main()
{
void (X::*f_ptr)()=&X::f;
X* x=new X();
(x->*f_ptr)();
delete x;
}
実行結果は以下となります。
f
->*は上記のように、メンバ関数のアドレスを保持しているポインタに対して、オブジェクトを示すポインタ(上記の場合x)を利用して呼び出す場合に使います。この演算子もオーバーロードが可能です。
#include<iostream>
struct X{
void f(){std::cout<<__func__<<std::endl;}
void operator->*(void (X::*mem_ptr)())
{
(this->*mem_ptr)();
}
};
int main()
{
void (X::*f_ptr)()=&X::f;
X x;
x->*f_ptr;
}
実行結果は以下の通りです。
f
とここまで取り上げておいてなのですが、一般的に、このPointer to Member演算子をオーバーロードする機会はあまり多くありません。尚、Pointer to Member演算子は非メンバ関数として定義することもできますが、用途としては推奨されないでしょう。
#include<iostream>
struct X{
void f(){std::cout<<__func__<<std::endl;}
};
void operator->*(X& t,void (X::*mem_ptr)())
{
return (t.*mem_ptr)();
}
int main()
{
void (X::*f_ptr)()=&X::f;
X x;
x->*f_ptr;
}
9.4.14 比較演算子
比較演算子(<、>、<=、>=)もオーバーロードする事ができます。まずは以下のコードを見てください。
#include<iostream>
struct X{
constexpr X(int a):a_(std::move(a)){}
int a_;
constexpr bool operator<(const X& other)const noexcept
{
return a_<other.a_;
}
constexpr bool operator>(const X& other)const noexcept
{
return a_>other.a_;
}
constexpr bool operator<=(const X& other)const noexcept
{
return a_<=other.a_;
}
constexpr bool operator>=(const X& other)const noexcept
{
return a_>=other.a_;
}
};
int main()
{
X x1(1),x2(2);
std::cout<<std::boolalpha<<(x1<x2)<<std::endl;
std::cout<<(x1>x2)<<std::endl;
std::cout<<(x1<=x2)<<std::endl;
std::cout<<(x1>=x2)<<std::endl;
}
実行結果は以下の通りです。
true
false
true
false
単純に演算子に期待できる動作を実装します。比較演算子は非メンバ関数として定義する事ができ、非メンバ関数として実装する方が一般的と言えます。
#include<iostream>
struct X{
constexpr X(int a):a_(std::move(a)){}
private:
friend constexpr bool operator<(const X& l,const X& r)noexcept
{
return l.a_<r.a_;
}
friend constexpr bool operator>(const X& l,const X& r)noexcept
{
return l.a_>r.a_;
}
friend constexpr bool operator<=(const X& l,const X& r)noexcept
{
return l.a_<=r.a_;
}
friend constexpr bool operator>=(const X& l,const X& r)noexcept
{
return l.a_>=r.a_;
}
int a_;
};
int main()
{
X x1(1),x2(2);
std::cout<<std::boolalpha<<(x1<x2)<<std::endl;
std::cout<<(x1>x2)<<std::endl;
std::cout<<(x1<=x2)<<std::endl;
std::cout<<(x1>=x2)<<std::endl;
}
実行結果は同じです。尚、これら比較演算子は、<か>を実装してしまえば後はそれを使って実装する事が可能です。
#include<iostream>
struct X{
constexpr X(int a):a_(std::move(a)){}
private:
friend constexpr bool operator<(const X& l,const X& r)noexcept
{
return l.a_<r.a_;
}
friend constexpr bool operator>(const X& l,const X& r)noexcept
{
return r.a_<l.a_;
}
friend constexpr bool operator<=(const X& l,const X& r)noexcept
{
return !(l.a_>r.a_);
}
friend constexpr bool operator>=(const X& l,const X& r)noexcept
{
return !(l.a_<r.a_);
}
int a_;
};
int main()
{
X x1(1),x2(2);
std::cout<<std::boolalpha<<(x1<x2)<<std::endl;
std::cout<<(x1>x2)<<std::endl;
std::cout<<(x1<=x2)<<std::endl;
std::cout<<(x1>=x2)<<std::endl;
}
実行結果は変わりません。
9.4.15 等価比較演算子
等価比較演算子(==、!=)もオーバーロードする事ができます。まずは以下のコードを見てください。
#include<iostream>
struct X{
constexpr X(int x):x_(std::move(x)){}
constexpr bool operator==(const X& other)const noexcept
{
return x_==other.x_;
}
constexpr bool operator!=(const X& other)const noexcept
{
return x_!=other.x_;
}
private:
int x_;
};
int main()
{
X x1(10);
X x2=x1;
std::cout<<std::boolalpha<<(x1==x2)<<std::endl;
std::cout<<(x1!=x2)<<std::endl;
}
実行結果は以下の通りです。
true
false
単純に演算子に期待できる動作を実装します。等価比較演算子は非メンバ関数としても定義する事ができ、一般的には非メンバ関数として実装する事が多いでしょう。
#include<iostream>
struct X{
constexpr X(int x):x_(std::move(x)){}
private:
friend constexpr bool operator==(const X& l,const X& r)noexcept
{
return l.x_==r.x_;
}
friend constexpr bool operator!=(const X& l,const X& r)noexcept
{
return l.x_!=r.x_;
}
int x_;
};
int main()
{
X x1(10);
X x2=x1;
std::cout<<std::boolalpha<<(x1==x2)<<std::endl;
std::cout<<(x1!=x2)<<std::endl;
}
実行結果は変わりません。尚、等価比較演算子は比較演算子が定義されていればそれらを使って実装する事が可能です。
#include<iostream>
struct X{
constexpr X(int x):a_(std::move(x)){}
private:
friend constexpr bool operator<(const X& l,const X& r)noexcept
{
return l.a_<r.a_;
}
friend constexpr bool operator>(const X& l,const X& r)noexcept
{
return r.a_<l.a_;
}
friend constexpr bool operator==(const X& l,const X& r)noexcept
{
return !(l<r) and !(l>r);
}
friend constexpr bool operator!=(const X& l,const X& r)noexcept
{
return !(l==r);
}
int a_;
};
int main()
{
X x1(10);
X x2=x1;
std::cout<<std::boolalpha<<(x1==x2)<<std::endl;
std::cout<<(x1!=x2)<<std::endl;
}
実行結果は変わりません。
9.4.16 論理演算子
論理演算子(&&、||)もオーバーロードする事ができます。まずは以下のコードを見てください。
#include<iostream>
struct X{
constexpr X(bool x):a_(std::move(x)){}
constexpr bool operator&&(const X& other)const noexcept
{
return a_&&other.a_;
}
constexpr bool operator||(const X& other)const noexcept
{
return a_||other.a_;
}
private:
bool a_;
};
int main()
{
X x1=true;
X x2=false;
std::cout<<std::boolalpha<<(x1&&x2)<<std::endl;
std::cout<<(x1||x2)<<std::endl;
}
実行結果は以下の通りです。
false
true
論理演算子は非メンバ関数として定義する事ができ、一般的には非メンバ関数として定義する事が多いでしょう。
#include<iostream>
struct X{
constexpr X(bool x):a_(std::move(x)){}
private:
friend constexpr bool operator&&(const X& l,const X& r)noexcept
{
return l.a_&&r.a_;
}
friend constexpr bool operator||(const X& l,const X& r)noexcept
{
return l.a_||r.a_;
}
bool a_;
};
int main()
{
X x1=true;
X x2=false;
std::cout<<std::boolalpha<<(x1&&x2)<<std::endl;
std::cout<<(x1||x2)<<std::endl;
}
実行結果は変わりません。尚、&&は!と||`が定義されていた場合それらを用いて実装する事ができます。
#include<iostream>
struct X{
constexpr X(int a):a_(std::move(a)){}
constexpr explicit operator bool()const noexcept
{
return a_;
}
constexpr bool operator!()const noexcept
{
return !bool(*this);
}
private:
friend constexpr bool operator||(const X& l,const X& r)noexcept
{
return l.a_||r.a_;
}
friend constexpr bool operator&&(const X& l,const X& r)noexcept
{
return !(!l||!r);
}
bool a_;
};
int main()
{
X x1=true;
X x2=false;
std::cout<<std::boolalpha<<(x1&&x2)<<std::endl;
std::cout<<(x1||x2)<<std::endl;
}
実行結果は変わりません。
9.4.17 複合代入演算子
複合代入演算子(+=、-=、\*=、/=、%=、<<=、>>=、&=、|=、^=)もオーバーロードする事ができます。
#include<iostream>
#include<limits>
struct X{
constexpr X(int a):a_(std::move(a)){}
constexpr X& operator+=(const X& other)noexcept
{
a_+=other.a_;
return *this;
}
constexpr X& operator-=(const X& other)noexcept
{
a_-=other.a_;
return *this;
}
constexpr X& operator*=(const X& other)noexcept
{
a_*=other.a_;
return *this;
}
constexpr X& operator/=(const X& other)noexcept
{
a_/=other.a_;
return *this;
}
constexpr X& operator<<=(const X& other)noexcept
{
a_<<=other.a_;
return *this;
}
constexpr X& operator>>=(const X& other)noexcept
{
a_>>=other.a_;
return *this;
}
constexpr X& operator%=(const X& other)noexcept
{
a_%=other.a_;
return *this;
}
constexpr X& operator&=(const X& other)noexcept
{
a_&=other.a_;
return *this;
}
constexpr X& operator|=(const X& other)noexcept
{
a_|=other.a_;
return *this;
}
constexpr X& operator^=(const X& other)noexcept
{
a_^=other.a_;
return *this;
}
private:
friend std::ostream& operator<<(std::ostream& os,const X& x)
{
return os<<x.a_;
}
int a_;
};
int main()
{
X x1=42;
X x2=std::numeric_limits<int>::max();
X x3=1;
std::cout<<(x1+=x3)<<std::endl;
std::cout<<(x1-=x3)<<std::endl;
std::cout<<(x1*=x3)<<std::endl;
std::cout<<(x1/=x3)<<std::endl;
std::cout<<(x1%=x3)<<std::endl;
std::cout<<(x2<<=x3)<<std::endl;
std::cout<<(x2>>=x3)<<std::endl;
std::cout<<(x2&=x3)<<std::endl;
std::cout<<(x2|=x3)<<std::endl;
std::cout<<(x2^=x3)<<std::endl;
}
実行結果は以下の通りです。
43
42
42
42
0
-2
-1
1
1
0
単純に実際の演算子に期待される動作を実装します。複合代入演算子は非メンバ関数として定義する事も可能ですが、一般的にはメンバ関数として定義する事が推奨されます。
尚、複合代入演算子のオーバーロードとは特別関係はありませんが、std::numeric_limits<int>::max()は、int型の最大値を表します。
9.4.18 コンマ演算子
コンマ演算子,をオーバーロードする事もできます。しかしこの演算子が利用される用途は多くはありません。また、意味論を考えると、本来オーバーロードするべきではありません。尚メンバ関数としても非メンバ関数としても定義できます。以下は、コンマ演算子のオーバーロードの一例ですが、推奨されるものではありません。
#include<iostream>
struct Functor{
void operator()(int x)const{std::cout<<x<<std::endl;}
};
struct X{
constexpr X(int a):a_(std::move(a)){}
void operator,(const Functor& f){f(a_);}
private:
int a_;
};
struct Y{
constexpr Y(int a):a_(std::move(a)){}
private:
int a_;
friend void operator,(const Y&,const Functor&);
};
void operator,(const Y& y,const Functor& f)
{
f(y.a_);
}
int main()
{
X x(10);
x,Functor();
Y y(20);
y,Functor();
}
実行結果は以下の通りです。
10
20
9.4.19 代入演算子のオーバーロード
代入演算子に関しては、「9.2.8 コピー代入」で、実は既に取り上げていました。基本的な内容はこの内容だけで十分です。代入演算子は、非メンバ関数として定義する事はでいません。
9.4.20 new/delete(usual new/delete)
new/delete演算子すらも、なんとオーバーロードすることができるのです。まず本稿では、より一般的なusual new/deleteのオーバーロードについて説明します。
さて、まずはじめに、ここで種明かしのようになりますが、「第7章動的な領域確保」で行ったnew/delete演算子の操作は、そもそも標準で用意されている、グローバル領域に暗黙的に定義されたoperator new、operator deleteを呼び出していたのです。
以下らがプログラムの翻訳単位で暗黙的に定義されます。
void* operator new(std::size_t);
void* operator new(std::size_t, std::align_val_t);
void operator delete(void*) noexcept;
void operator delete(void*, std::size_t) noexcept;
void operator delete(void*, std::align_val_t) noexcept;
void operator delete(void*, std::size_t, std::align_val_t) noexcept;
void* operator new[](std::size_t);
void* operator new[](std::size_t, std::align_val_t);
void operator delete[](void*) noexcept;
void operator delete[](void*, std::size_t) noexcept;
void operator delete[](void*, std::align_val_t) noexcept;
void operator delete[](void*, std::size_t, std::align_val_t) noexcept;
通常のnew/delete演算子を実行すると、これらの暗黙定義された関数が実行されることになっています。
operator new/deleteの第二引数、std::size_tにはそのオブジェクトのバイト数が渡されます。
std::alignval_tは、アライメントが、標準で定義されている__STDCPP_DEFAULT_NEW_ALIGNMENT__というマクロ定数よりも大きいオブジェクトと使われた場合にそのアライメントを送信するために使われます(アライメントについてはコラムを参照)。これらと同じシグネチャでユーザーがグローバル領域にnew/deleteを定義した場合、翻訳段階でその定義によって完全に上書きされます。
ではこれらを全て独自に定義して、これまで説明してきたものを確認してみましょう。
#include<cstdio>
#include<cstdlib>
struct liner{
static void line()
{
for(std::size_t i=0; i<50; ++i)printf("-");
puts("");
}
liner(){line();}
~liner(){line();}
};
// Single object operator new
void* operator new(std::size_t x) // (1)
{
liner _;
std::printf("1 param op %s std::size_t is %ld\n",__func__,x);
return std::malloc(x);
}
void* operator new(std::size_t x,std::align_val_t align) // (2)
{
liner _;
std::printf("2 param op %s std::size_t is %ld\n",__func__,x);
std::printf("align is %ld\n",static_cast<std::size_t>(align));
return aligned_alloc(static_cast<std::size_t>(align),x);
}
// Array object operator new
void* operator new[](std::size_t x) // (3)
{
liner _;
std::printf("1 param op %s std::size_t is %ld\n",__func__,x);
return std::malloc(x);
}
void* operator new[](std::size_t x,std::align_val_t align) // (4)
{
liner _;
std::printf("2 params op %s std::size_t is %ld\n",__func__,x);
std::printf("align is %ld\n",static_cast<std::size_t>(align));
return aligned_alloc(static_cast<std::size_t>(align),x);
}
// Single object operator delete
void operator delete(void* ptr)noexcept // (5)
{
liner _;
std::printf("1 param op %s\n",__func__);
std::free(ptr);
}
void operator delete(void* ptr,std::size_t x)noexcept // (6)
{
liner _;
std::printf("2 params op %s std::size_t is %ld\n",__func__,x);
std::free(ptr);
}
void operator delete(void* ptr,std::align_val_t align)noexcept // (7)
{
liner _;
std::printf("2 param op %s\n",__func__);
std::printf("align is %ld\n",static_cast<std::size_t>(align));
std::free(ptr);
}
void operator delete(void* ptr,std::size_t x,std::align_val_t align)noexcept // (8)
{
liner _;
std::printf("3 param op %s std::size_t is %ld\n",__func__,x);
std::printf("align is %ld\n",static_cast<std::size_t>(align));
std::free(ptr);
}
// Array object operator delete
void operator delete[](void* ptr)noexcept // (9)
{
liner _;
std::printf("1 param op %s\n",__func__);
std::free(ptr);
}
void operator delete[](void* ptr,std::size_t x)noexcept // (10)
{
liner _;
std::printf("2 params op %s std::size_t is %ld\n",__func__,x);
std::free(ptr);
}
void operator delete[](void* ptr,std::align_val_t align)noexcept // (11)
{
liner _;
std::printf("2 params op %s\n",__func__);
std::printf("align is %ld\n",static_cast<std::size_t>(align));
std::free(ptr);
}
void operator delete[](void* ptr,std::size_t x,std::align_val_t align)noexcept // (12)
{
liner _;
std::printf("3 params op %s std::size_t is %ld\n",__func__,x);
std::printf("align is %ld\n",static_cast<std::size_t>(align));
std::free(ptr);
}
struct X{
X(){std::puts(__func__);}
~X(){std::puts(__func__);}
char a[200];
};
struct alignas((__STDCPP_DEFAULT_NEW_ALIGNMENT__*2)) Y{
Y(){std::puts(__func__);}
~Y(){std::puts(__func__);}
};
int main()
{
delete new X();
delete new Y();
delete[] new X[3];
delete[] new Y[3];
}
実行結果は以下の通りです。
--------------------------------------------------
1 param op operator new std::size_t is 200
--------------------------------------------------
X
~X
--------------------------------------------------
2 params op operator delete std::size_t is 200
--------------------------------------------------
--------------------------------------------------
2 param op operator new std::size_t is 32
align is 32
--------------------------------------------------
Y
~Y
--------------------------------------------------
3 param op operator delete std::size_t is 32
align is 32
--------------------------------------------------
--------------------------------------------------
1 param op operator new [] std::size_t is 608
--------------------------------------------------
X
X
X
~X
~X
~X
--------------------------------------------------
2 params op operator delete [] std::size_t is 608
--------------------------------------------------
--------------------------------------------------
2 params op operator new [] std::size_t is 96
align is 32
--------------------------------------------------
Y
Y
Y
~Y
~Y
~Y
--------------------------------------------------
3 params op operator delete [] std::size_t is 128
align is 32
--------------------------------------------------
このようにグローバル名前空間にoperator new/deleteをオーバーロードすると、型の内部のメンバ関数としてoperator new/deleteが独自にオーバーロードされていた場合を除いて、全ての型に対するnew/delete操作でこのオーバーロードされたoperator new/deleteが呼び出されるようになります。 実行結果からも、様々なものが表されていますね。
オーバーロードは上から単一のオブジェクト用のoperator new、複数のオブジェクト用のoperator new[]、単一のオブジェクトのoperator delete、複数のオブジェクト用のoperator delete[]と記述されています(linerという型を作っていますが、その名の通り単に罫線を引くためだけのものなので、本項の内容とは特別関係ありません。)。
main関数内の実行過程をここで順に見ていきましょう。
main関数では、まず一番初めに単一のX型をnewしています。この時呼び出されるのは(1)のoperator newです。その後、出力からわかるようにXのコンストラクタが呼ばれています。main関数ですぐさまそれをdeleteしていますので、その後の即座にXのデストラクタが呼ばれていることがわかります。その後、operator deleteが呼び出されます。この時呼び出されるのは(6)のoperator deleteです。次に、単一の
Y型をnewしています。Y型の定義部分に注目してください。struct alignas((\_\_STDCPP\_DEFAULT\_NEW\_ALIGNMENT\_\_\*2)) Yとなっています。これは、Y型のインスタンスを特定のバイト境界でメモリに置けとコンパイラに対して示しています。バイト境界についてもコラムのアライメントの項目で取り上げますが、簡単に言えば、例えば4バイト境界の位置にアライメントした場合、オブジェクトはメモリ上の4の倍数のアドレスに配置され、8バイト境界の位置にアライメントした場合、オブジェクトはメモリ上の8の倍数のアドレスに配置される事となります。そしてその指定はalignasを使う事で可能です。今回の場合、Yの宣言部分でalignasを指定しているため、インスタンスは全てアライメントされなければなりません。そしてそのアライメント値を\_\_STDCPP\_DEFAULT\_NEW\_ALIGNMENT\_\_の二倍としています。std::align\_val\_t版のoperator new/deleteが呼ばれるのは、呼び出しに関連するオブジェクトのアライメントが\_\_STDCPP\_DEFAULT\_NEW\_ALIGNMENT\_\_よりも大きかった場合ですから、その二倍を指定しているのでstd::align\_val\_t版が呼び出されるのは必然と言えます。よって、この時newで呼び出されるのは、(2)のoperator newです。(2)のoperator newでは、std::aligned\_allocが呼び出されていますが、これは任意のアライメント値でアライメントしつつ領域を確保することができる標準関数です。これは、<cstdlib>に定義されています。さてその後、先ほどと同じくコンストラクタが呼び出され、 即デストラクタが呼び出されています。その後、std::align\_val\_t版のoperator deleteが呼び出されます、この時呼び出されるのは(8)のoperator deleteです。次に、配列の
X型をnewしています。この時呼び出されるのは、(3)のoperator new[]です。今回要請した要素数は3なので、コンストラクタ、デストラクタがそれぞれ三度呼び出されています。operator deleteが呼び出されます。この時呼び出されるのは(10)のoperator deleteです。最後に、配列の
Y型をnewしています。この時呼び出されるのは、(4)のoperator new[]です。今回要請した要素数は3なので、コンストラクタ、デストラクタがそれぞれ三度呼び出されています。operator deleteが呼び出されます。この時呼び出されるのは(12)のoperator deleteです。
このように、グローバルに定義したoperator new/deleteは、最もシグネチャの合う、引数の多いoperator deleteが優先的に呼び出されます。
また、一つ注目して頂きたいのが、全てのoperator deleteに対してnoexcept指定がされているということです。これは、全てのoperator deleteは、例外を投げないという標準の要件によるものです。標準の要件なので、当然ながら、その要件は満たすべきです。
さて、次にoperator new/deleteをクラススコープでメンバ関数としてオーバーロードしてみましょう。ソースコードは殆ど変わりませんが、挙動が若干変化します。
#include<cstdio>
#include<cstdlib>
struct liner{
static void line()
{
for(std::size_t i=0; i<50; ++i)printf("-");
puts("");
}
liner(){line();}
~liner(){line();}
};
struct X{
X(){std::puts(__func__);}
~X(){std::puts(__func__);}
char a[200];
void* operator new(std::size_t x) // (1)
{
liner _;
std::printf("1 param op %s std::size_t is %ld\n",__func__,x);
return std::malloc(x);
}
void* operator new[](std::size_t x) // (2)
{
liner _;
std::printf("1 param op %s std::size_t is %ld\n",__func__,x);
return std::malloc(x);
}
void operator delete(void* ptr)noexcept // (3)
{
liner _;
std::printf("1 param op %s\n",__func__);
std::free(ptr);
}
void operator delete(void* ptr,std::size_t x)noexcept // (4)
{
liner _;
std::printf("2 params op %s std::size_t is %ld\n",__func__,x);
std::free(ptr);
}
void operator delete[](void* ptr)noexcept // (5)
{
liner _;
std::printf("1 param op %s\n",__func__);
std::free(ptr);
}
void operator delete[](void* ptr,std::size_t x)noexcept // (6)
{
liner _;
std::printf("2 params op %s std::size_t is %ld\n",__func__,x);
std::free(ptr);
}
};
struct alignas((__STDCPP_DEFAULT_NEW_ALIGNMENT__*2)) Y{
Y(){std::puts(__func__);}
~Y(){std::puts(__func__);}
void* operator new(std::size_t x,std::align_val_t align)noexcept // (7)
{
liner _;
std::printf("2 param op %s std::size_t is %ld\n",__func__,x);
std::printf("align is %ld\n",static_cast<std::size_t>(align));
return aligned_alloc(static_cast<std::size_t>(align),x);
}
void* operator new[](std::size_t x,std::align_val_t align) // (8)
{
liner _;
std::printf("2 params op %s std::size_t is %ld\n",__func__,x);
std::printf("align is %ld\n",static_cast<std::size_t>(align));
return aligned_alloc(static_cast<std::size_t>(align),x);
}
void operator delete(void* ptr,std::align_val_t align)noexcept // (9)
{
liner _;
std::printf("2 param op %s\n",__func__);
std::printf("align is %ld\n",static_cast<std::size_t>(align));
std::free(ptr);
}
void operator delete(void* ptr,std::size_t x,std::align_val_t align)noexcept // (10)
{
liner _;
std::printf("3 param op %s std::size_t is %ld\n",__func__,x);
std::printf("align is %ld\n",static_cast<std::size_t>(align));
std::free(ptr);
}
void operator delete[](void* ptr,std::align_val_t align)noexcept // (11)
{
liner _;
std::printf("2 params op %s\n",__func__);
std::printf("align is %ld\n",static_cast<std::size_t>(align));
std::free(ptr);
}
void operator delete[](void* ptr,std::size_t x,std::align_val_t align)noexcept // (12)
{
liner _;
std::printf("3 params op %s std::size_t is %ld\n",__func__,x);
std::printf("align is %ld\n",static_cast<std::size_t>(align));
std::free(ptr);
}
};
int main()
{
delete new X();
delete new Y();
delete[] new X[3];
delete[] new Y[3];
}
実行結果は以下の通りです。
--------------------------------------------------
1 param op operator new std::size_t is 200
--------------------------------------------------
X
~X
--------------------------------------------------
1 param op operator delete
--------------------------------------------------
--------------------------------------------------
2 param op operator new std::size_t is 32
align is 32
--------------------------------------------------
Y
~Y
--------------------------------------------------
2 param op operator delete
align is 32
--------------------------------------------------
--------------------------------------------------
1 param op operator new [] std::size_t is 608
--------------------------------------------------
X
X
X
~X
~X
~X
--------------------------------------------------
1 param op operator delete []
--------------------------------------------------
--------------------------------------------------
2 params op operator new [] std::size_t is 128
align is 32
--------------------------------------------------
Y
Y
Y
~Y
~Y
~Y
--------------------------------------------------
2 params op operator delete []
align is 32
--------------------------------------------------
まず少し不思議に思えるのが、static修飾なしにクラスのメンバとしてoperator new/deleteを定義しているのにも関わらず、まるでstaticであるかのように呼び出せています。これは、一つの決定事項があるために実現できています。その決定事項とは、全てのクラススコープのoperator new/deleteは、必ずstaticメンバ関数となるという事です。よって、staticキーワードを付与せずとも、operator new/deleteは特別にstaticメンバ関数となります(staticキーワードを明示的に付与しても良い)。
さて、実行結果から伺えるように、クラスメンバとしてoperator new/deleteをオーバーロードした場合、グローバル領域でオーバーロードした場合と異なるoperator deleteが呼び出されている事が分かります。これは優先度の変化というわけではありません。operator deleteのすべてのパターンをクラススコープでオーバーロードした場合、void*一つを受け付けるoperator delete、void*に加えてstd::alignval_tを受け付けるoperator deleteはusual delete(通常のdelete)として、void*に加えてstd::size_tを受け付けるoperator deleteはplacement deleteとして捉えられるためです。
/* */
/* []といった配列版を省略... */
/* */
// グローバルスコープ ...
void operator new(std::size_t); // usual new
void operator delete(void*)noexcept; // usual delete
void operator delete(void*,std::align_val_t)noexcept; // usual delete
void operator delete(void*,std::size_t)noexcept; // usual delete
// クラススコープ...
struct X{
void operator new(std::size_t); // usual new
void operator delete(void*)noexcept; // usual delete
void operator delete(void*,std::align_val_t)noexcept; // usual delete
void operator delete(void*,std::size_t)noexcept; // placement delete
};
operator new/deleteは、usualなnewであればusualなdeleteを、placementなnewであればplacementなdeleteを呼ぶため、usual deleteであるかplacement deleteであるかによって、結果として呼び出せるものが変わってくるのです。
...とここまでは全てのパターンのusualなoperator new/deleteをオーバーロードしてきましたが、文法的には全てのパターンを網羅せずとも違法なプログラムとはなりません。しかし、汎用性を考えると、operator new/deleteをオーバーロードするのであれば網羅するのが好ましいです。
9.4.21 Placement new / delete(placement/Non-allocating forms new/delete )
本項ではこれまでで説明してきたusual new/deleteとは少し異なる領域の確保/活用方法を説明します。
まず、new演算子には、「7.6 動的な領域確保」で述べたような使い方に加えて、情報を付加するような構文があり、標準で定義されたものは大きく二種類に分類することができます。これらはplacement new(しばしば配置new)と呼ばれます。
placement-newによる情報付加
まず一つ目ですが、new演算子は、領域の確保に失敗するとstd::bad_alloc例外を送出しますが、従来の古いしきたりのように、例外ではなくnullptrを返すように設定することができます(しかし、これは現代のC++ではdeprecatedとされているため、nullptrを返すようにするべきではありません)。
#include<new>
struct X{};
int main()
{
X* ptr=new(std::nothrow) X();
if(p)delete ptr;
}
new()と記述して、そこにstd::nothrowを設定することでnullptrを返すようになります(メモリ領域の確保中に起きる例外に限ります。オブジェクト生成中の例外、つまりコンストラクタ実行中の例外が発生した場合はそのまま例外を投げることになります)。std::nothrowは<new>ヘッダに定義されているstd::nothrow_t型の定数です。またこの構文はnew演算子をオーバーロードすることで使うことができる構文です。上記の場合では、これまた<new>ヘッダの中で既にplacement newがオーバーロードされているため、使うことができています。
これらは、<new>ヘッダ内で以下のように宣言されています。
void* operator new(std::size_t, const std::nothrow_t&)noexcept;
void* operator new[](std::size_t, const std::nothrow_t&)noexcept;
void operator delete(void*, const std::nothrow_t&)noexcept;
void operator delete[](void*, const std::nothrow_t&)noexcept;
全てがnoexcept修飾されていることに注目してください。std::nothrowによって例外は投げないと指定していることからその明示性が伺えます。
この機能については、完全に独自的に新たにオーバーロードする事が可能です。以下では例として、領域確保が失敗した場合、ソースコード中の該当行を出力させるといった事をしています。
#include<cstdio>
#include<cstdlib>
struct X{
void* operator new(std::size_t size) // usual new
{
return std::malloc(size);
}
void* operator new([[maybe_unused]] std::size_t size,std::size_t Line) // placement new
{
// void* ptr=std::malloc(size)
void* ptr=nullptr;
if(!ptr){
std::printf("Failed to allocate\n[LINE]:%ld\n",Line);
}
return ptr;
}
void operator delete(void* ptr)noexcept // usual delete
{
std::free(ptr);
}
void operator delete(void* ptr,std::size_t)noexcept // placement delete
{
if(ptr)std::free(ptr);
}
};
int main()
{
X* ptr=new(__LINE__) X;
if(ptr)delete ptr;
}
実行結果は以下となります。
Failed to allocate
[LINE]:32
コメントアウトしてあるように、意図的に領域確保失敗のケースをシミュレートしています。コード中の[[maybe_unused]]とは、その変数を一切使わない事があっても、コンパイラに警告を出させないようにする抑制命令です。
ここで少し不思議なのが、placement newしか使わないはずなのに、何故かusual new/deleteが定義されているということです。これは、このコードが冗長であるわけではなく、絶対的に必要であるがためにusual new/deleteが定義されています。どのように必要なのでしょうか? まずは、placement new/deleteだけを定義した場合のplacement new/delete両者のシグネチャを見て見ましょう。
struct X{
void* operator new(std::size_t,std::size_t); // placement new
void operator delete(void*,std::size_t)noexcept; // placement delete ...ではない
};
さて、上記のplacement new/deleteはこのようなシグネチャで宣言されていますが、operator deleteに注目してください。実は、このdelete、コメントにもあるようにplacement deleteではなく、usual deleteとして定義されてしまうのです。その理由は、usual new/deleteの項で取り上げたように、void operator delete(void*,std::size_t)noexcept;というシグネチャは、usual deleteにもなりうるといった事に関連しています。このような定義のみのXはvoid operator delete(void*)を持ちません。そういった場合、void operator delete(void*,std::size_t)noexcept;といったシグネチャのoperator deleteは、placement deleteではなく、usual deleteとして定義されてしまうのです。void operator delete(void*,std::size_t)noexcept;をplacement deleteとして定義したい場合、void operator delete(void*)といったシグネチャのoperator usual delete(通常とは異なるアライメントに対応させるoperator new/deleteのusualなoperator deleteはvoid operator delete(void*,std::align_val_t)noexcept;となる)が定義されなければなりません。
よって、下記のように追加する必要があります。
struct X{
void* operator new(std::size_t,std::size_t); // placement new
void operator delete(void*); // usual delete
void operator delete(void*,std::size_t)noexcept; // placement delete
}
...しかし、これだけは不十分です。void* operator delete(void*,std::size_t)noexcept;をplacement deleteにするために定義したvoid operator delete(void*)というusual deleteですが、usual deleteが定義されているのならば、それの対となるusual newが定義されなければなりませんね。ということで、最終的に、operator new/deleteの宣言は以下のようにならなければならないのです。
struct X{
void* operator new(std::size_t); // usual deleteの対となるusual new
void* operator new(std::size_t,std::size_t); // placement new
void operator delete(void*)noexcept; // 下記のdeleteをplacement deleteとするためのusual delete
void operator delete(void*,std::size_t)noexcept; // placement delete
};
さて、少しややこしいところを終えたところで、引き続きプログラムの流れを追って見ましょう。
main関数内のplacement newを見てください。この部分で、型Xで独自に定義した引数らにデータを与えています。__LINE__と__FILE__は、予め標準で定義されてあるマクロであり、それぞれ該当する行数と、自身のファイル名が格納されており、それらの情報を転送する事で、このようなカスタマイズを達成しています。ただ今回は簡略化するために、領域確保に失敗した場合に単に文字列を出力するようにしていますが、本来であれば例外を投げるのが適切でしょう。例外についての詳細は後術しています。
Non-allocating forms
次に二つ目です。
さて、ここまでで説明してきた動的な領域確保は、主にヒープ領域から使うぶんの領域を確保していました。ここで、ヒープ領域から単純に領域を確保する際の短所を考察してみます。
- ヒープ領域から領域を確保するのは一般的にスタック領域から確保するよりも低速です。
- new演算子、malloc系関数を用いたヒープ領域からのリソース確保の方法は処理系のメモリ管理アルゴリズムに依存するため、ユーザー定義な独自の管理を行う事ができない
これらを解消するためには、ヒープ領域でない部分から領域を取ってくると良いかもしれません。
placement new構文は、それを可能にします。まずは領域をスタック領域から確保して、それを使うという事をしてみましょう。それをするためには、new/deleteをplacement newの形でオーバーロードしなければなりません。やっていることは、確保済みの領域から領域を取って来るといったところでしょうか。コードを見てしまった方が理解に容易いでしょう。以下に、方法を示します。
#include<iostream>
struct X{
X(){std::cout<<"ctor"<<std::endl;}
~X(){std::cout<<"dtor"<<std::endl;}
void* operator new(std::size_t,void* ptr){return ptr;}
void operator delete(void*,void*)noexcept{}
};
int main()
{
char resource[sizeof(X)];
X* ptr=new(resource) X;
ptr->~X();
}
実行結果は以下の通りです。
ctor
dtor
まずmain内では、char型の配列を用意しています。そのサイズは、X型と同じバイト長です。char型は必ず1 byteであることが定められていますから、その領域ぶんのサイズを確保できれば、当然ながら互換性がある事になります。今回は、あらかじめ用意した領域はX型1つ分ということになります。
次にX型内部を見て見ましょう。new/delete演算子をオーバーロードしていることが伺えます。先ほどのusual new/deleteとは異なり、第二引数でvoid*を受け取っていますね。
placement new/deleteをオーバーロードする際はシグネチャが以下のようにならなくてはなりません。
void* operator new(std::size_t,Args...);
void* operator delete(std::size_t,Args...)noexcept;
Args...というのは、任意の型で任意のパラメータ数であるという意味です。usual new/deleteと同じく、placement new/deleteも互いに対となるplacement new/deleteを適切に定義しなければなりません。
最後に注目して欲しいのが、main関数内でデストラクタを明示的に呼び出していること、またplacement newに対するplacement deleteを呼び出していないです。
まずplacement newは、placement newによって新たに領域を確保しているわけではないので、deleteする必要がないのです。ただ、placement deleteを呼び出すことはできます。しかし呼び出したところで何も起こりません。
char resource[sizeof(X)];
X* ptr=new(resource) X;
X::operator delete(ptr,ptr);
しかし、このままだと、placement operator newが行う、オブジェクトの生成、つまりコンストラクタの呼び出しに対して行われるべき、デストラクタの呼び出しが行われなくなってしまうため、デストラクタを明示的に呼び出す必要があるのです。 しかし、placement operator deleteは呼び出す必要もないのになぜ定義しておかなければならないのでしょうか。それは、placement operator newの後、コンストラクタで例外が投げられた場合にまず対となるoperator deleteが呼び出されるためです。
尚上記のコードは、<new>ヘッダーに予め以下のように定義されている、グローバルなoperator placement new/deleteを使えば、上記のように、独自にクラス内でオーバーロードせずとも同様のののことが実現できます(<new>ヘッダには下記の他にも様々なoperator new/deleteに対するoperator overloadingがされていますが、placement new/deleteを特出して掲載しています)。
// <new>ヘッダ内
void* operator new (std::size_t size, void* ptr) noexcept;
void* operator new[](std::size_t size, void* ptr) noexcept;
void operator delete (void* ptr, void*) noexcept;
void operator delete[](void* ptr, void*) noexcept;
これらを使ってみましょう。
#include<iostream>
#include<new>
struct X{
X(){std::cout<<"ctor"<<std::endl;}
~X(){std::cout<<"dtor"<<std::endl;}
};
int main()
{
char resource[sizeof(X)];
X* ptr=new (resource) X();
ptr->~X();
}
実行結果は以下の通りです。
ctor
dtor
このように、わざわざクラス内に独自的にplacement new/deleteをオーバーロードせずとも同様の内容が達成できます。これで事足りるのであれば、独自的に実装するよりも、<new>ヘッダをインクルードしてそのコードを用いる方が、信頼性の面から見ても良いコードであると言えます。
尚、placement new/deleteに対する定義は標準ライブラリヘッダー(`
このようにplacement newを使ってメモリ割当てを行うシステムを、アロケータと言い、アロケータによる管理の基使われる予定である予め確保された領域をメモリプールと言います。標準で用意されたライブラリの中でも、独自のアロケータでメモリ管理ができるように、設定の引数が設けられていたりするのですが、詳細は第12章のSTLと標準ライブラリで取り上げることとします。
さて、ここまでスタック領域からリソースを取れるということを売りにしてきたplacement newですが、ヒープ領域、静的領域からも領域を取得することは可能です。
#include<new>
struct X{};
char resource[sizeof(X)];
int main()
{
X* ptr=new X;
ptr=new(ptr) X; // ヒープから取得してある領域をplacement newで割り当てる。同じアドレスなので上書きしても大丈夫
ptr->~X();
delete ptr;
ptr=new(resource) X; // 静的領域のresourceで割り当てる。
ptr->~X();
}
スタック領域の確保は、どうしても固定長(コンパイル時に定まった値)でなければならないため、メモリプールの領域も可変にしたい、しかし連続的に領域の確保/破棄がしたいためにメモリプールは欲しいといった場合では対応できません。そう行った場合は、以下のようにヒープ領域からメモリプールを確保してそこをplacement newするという手段も考えられます。
メモリリソースの断片化
ここで一度、メモリリソースの断片化について取り上げます。
リソース領域から、多くの回数領域の確保、解放の操作を繰り返すと、断片化が発生してしまい、希望する領域サイズ分が、リソース中の空き領域の合計サイズと同等以上あったとしても、連続した領域で確保する事ができないため(ある程度のサイズのデータ領域を確保しようとした時、私たちに与えられている領域確保の方法は配列であり、配列は連続した領域に確保されるという事を思い出してください。)、領域の確保に失敗すると行った事が起こり得るようになります。
断片化していくメモリの様子を図に示しました。この領域確保の手法は、ファーストフィットと呼ばれるもので、主に一番最初に見つかった確保可能な領域を使用するアルゴリズムです。
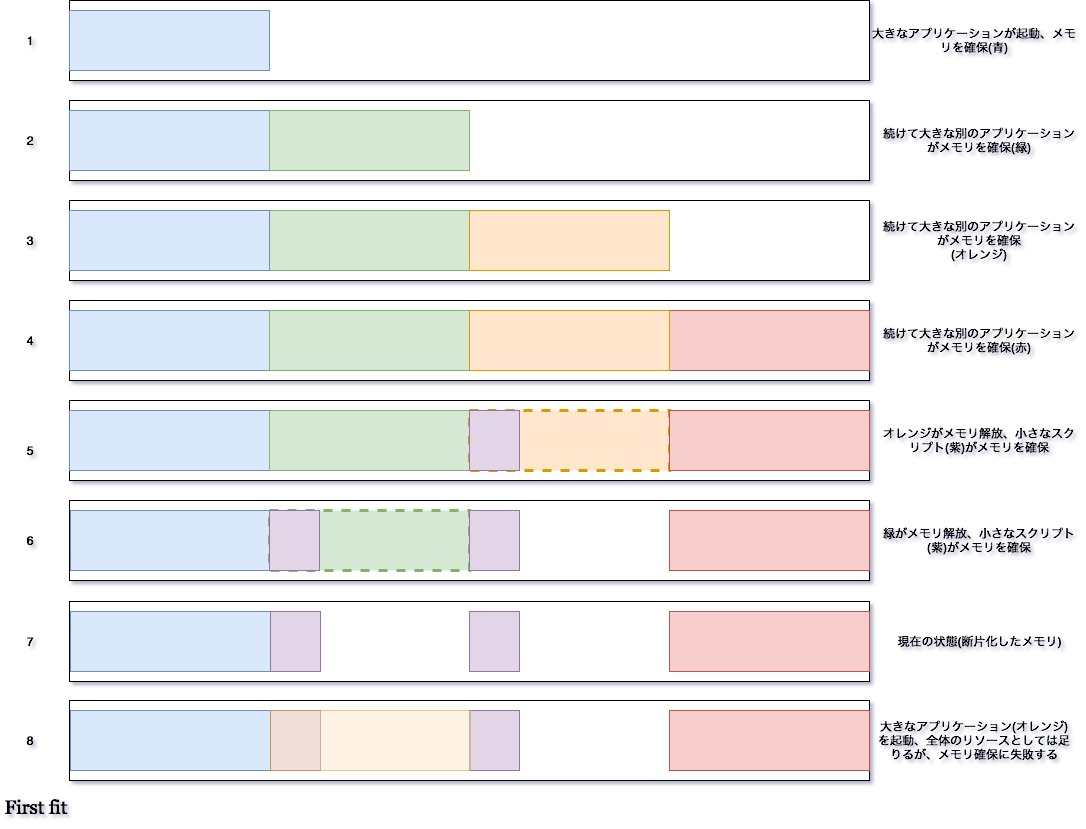
このような事を防ぐためには、二つの方法が考えられますね。
- 断片化を防止する
- 断片化したリソースを整理し再利用可能にする
まず断片化がおきないように領域確保を行うこと、これは可能であれば最も好ましい解決方法でしょう。後述する断片化したリソースの再整理は、再整理するだけの処理能力をやはり覆わなくてはなりません。それをなしに、初めから効率の良いリソース確保ができるのであれば、それが最も良いパフォーマンスの出し方であることは想像に容易いでしょう。しかし、断片化が起きないようにするリソース確保の手法は一概にこれであるとすることはできません。何故ならば、最適な確保の仕方も、要求される条件や処理系に依存するからです。前述したファーストフィットに加え、ベストフィットといった空き容量中で要求を満たすサイズ以上の最も近いサイズ領域を使うというアルゴリズムなど、単純な手法の他にも様々な活用方法が考案されています。よって、ここでは深く触れませんが、その概要がわかりやすくこちらのスライドで紹介されていますので、興味のある方は調べてみるのも良いでしょう。
次に、断片化を整理する、デフラグという操作を行う事で再利用可能にする方法です。デフラグの手法は様々ですが、内容としては断片化したリソース領域を一方方向に全てずらして詰めてあげる(メモリコンパクション)といった具合に行います。デフラグの方法については、まだ説明していませんが、主に演算子オーバーロードなどを用いて領域確保の手法や管理方法を各個人が再定義する事で可能となりますが、これについての詳細はまた一つ大きな分野であるため、本章では取り扱いません。
9.4.22 演算子のオーバーロードまとめ
メモリリソースの話などで少し脱線してしまいましたが、ここでオーバーロード可能な演算子と可能でない演算子をま止めて起きましょう。
| オーバーロード可能 | |||||
|---|---|---|---|---|---|
new |
delete |
new[] |
delete[] |
||
+ |
- |
* |
/ |
||
% |
^ |
& |
`\ | ` | |
~ |
! |
= |
< |
||
> |
+= |
-= |
*= |
||
/= |
%= |
^= |
&= |
||
| `\ | =` | << |
>> |
>>= |
|
<<= |
== |
!= |
<= |
||
>= |
&& |
`\ | \ | ` | ++ |
-- |
, |
->* |
-> |
||
( ) |
[ ] |
| オーバーロード不可能 | |||
|---|---|---|---|
. |
.* |
:: |
?: |
9.4.23 ユーザー定義リテラル
まずリテラルとは、定数を示します。以下のコードを見てみましょう。
#include<iostream>
void f(float)
{
std::cout<<"float"<<std::endl;
}
void f(double)
{
std::cout<<"double"<<std::endl;
}
int main()
{
f(4.2);
}
実行結果は以下の通りです。
double
4.2という数値がリテラルです。この時、何気なく4.2という小数点値を扱っていますが、実行結果からも分かる通り、小数点リテラルに何も指定しなければその値はdouble型として扱われます。4.2という値をfloat型として利用したい場合、どのようにすれば良いのでしょうか。例えば、以下のような方法が考えられます。
#include<iostream>
void f(float)
{
std::cout<<"float"<<std::endl;
}
void f(double)
{
std::cout<<"double"<<std::endl;
}
int main()
{
f(static_cast<float>(4.2));
f(float(4.2));
}
実行結果は以下の通りです。
float
float
確かに、floatを受け取る方の関数が呼び出されましたが4.2というdouble型の値をfloat型にキャストしているだけですから、本質的な意味を成しておらず、単なる回避策に過ぎません。float型の4.2であると示すには以下のように、数値の末尾にfを添えてその意図を示します。
#include<iostream>
void f(float)
{
std::cout<<"float"<<std::endl;
}
void f(double)
{
std::cout<<"double"<<std::endl;
}
int main()
{
f(4.2f);
}
実行結果は以下の通りです。
float
このような末尾に添えたfをサフィックスと言います。
本項のタイトルであるユーザー定義リテラルというのは、このサフィックスを独自に定義する事でユーザーがリテラルに意味を持たせる事ができる機能です。
サフィックスをオーバーロードする機会として多いのは、そのリテラルの単位であったり、型を示したい場合に用いられます。
まずは、例として単位を表すためにこの機能を用いてみましょう。センチ、メートル、キロメートルを、簡易的に表現するクラスを作成し、それを表すサフィックスとして、cm、m、kmをユーザー定義でオーバーロードします。
#include<iostream>
struct metor;
struct kilometor;
struct centimetor{
explicit centimetor()=default;
constexpr centimetor(float value):value(std::move(value)){}
constexpr centimetor(const centimetor&)=default;
constexpr centimetor(const metor&);
constexpr centimetor(const kilometor&);
float value;
friend std::ostream& operator<<(std::ostream& os,const centimetor& c)
{
return os<<c.value;
}
};
struct metor{
explicit metor()=default;
constexpr metor(float value):value(std::move(value)){}
constexpr metor(const metor&)=default;
constexpr metor(const centimetor& x)noexcept(noexcept(x.value/100.0f)):value(x.value/100.0f){}
constexpr metor(const kilometor&);
float value;
friend std::ostream& operator<<(std::ostream& os,const metor& m)
{
return os<<m.value;
}
};
struct kilometor{
explicit kilometor()=default;
constexpr kilometor(float value):value(std::move(value)){}
constexpr kilometor(const kilometor&)=default;
constexpr kilometor(const centimetor& x)noexcept(noexcept(x.value/1000000.0f)):value(x.value/100000.0f){}
constexpr kilometor(const metor& x)noexcept(noexcept(x.value/1000.0f)):value(x.value/1000.0f){}
float value;
friend std::ostream& operator<<(std::ostream& os,const kilometor& k)
{
return os<<k.value;
}
};
constexpr centimetor::centimetor(const metor& x):value(x.value*100.0f){}
constexpr centimetor::centimetor(const kilometor& x):value(x.value*100000.0f){}
constexpr metor::metor(const kilometor& x):value(x.value*1000.0f){}
constexpr centimetor operator"" _cm(long double value) // リテラル演算子
{
return centimetor(std::move(value));
}
constexpr metor operator"" _m(long double value) // リテラル演算子
{
return metor(std::move(value));
}
constexpr kilometor operator"" _km(long double value) // リテラル演算子
{
return kilometor(std::move(value));
}
void f(centimetor centi)
{
std::cout<<centi<<"cm"<<std::endl;
}
void f(metor metor)
{
std::cout<<metor<<"m"<<std::endl;
}
void f(kilometor kilo)
{
std::cout<<kilo<<"km"<<std::endl;
}
int main()
{
f(100.0_cm); // オーバーロードしたリテラル演算子の利用
f(metor(100.0_cm));
f(kilometor(100.0_cm));
std::cout<<std::endl;
f(100.0_m); // オーバーロードしたリテラル演算子の利用
f(centimetor(100.0_m));
f(kilometor(100.0_m));
std::cout<<std::endl;
f(100.0_km); // オーバーロードしたリテラル演算子の利用
f(centimetor(100.0_km));
f(metor(100.0_km));
}
実行結果は以下の通りです。
100cm
1m
0.001km
100m
10000cm
0.1km
100km
1e+07cm
100000m
ユーザー定義リテラルを利用する際のシグネチャの書式は以下の通りです。
戻り値型 operator"" _サフィックス名(仮引数リスト)
このように定義された関数をリテラル演算子と言います。リテラル演算子のシグネチャは通常の演算子オーバーロードと特に変わりはありませんが、関数名に対して一つだけ規約があります。それは、サフィックス名の前に_(アンダースコア)を付与しなければならないという事です。アンダースコアで始まらないユーザー定義リテラルのサフィックス名は、標準C++標準によって予約されているため、定義してはならないのです。尚、アンダースコアに続いて大文字で始まる識別子や連続した 2 つ以上のアンダースコアを含む識別子は、ユーザー定義リテラルの規約とは関係なく予約された識別子名なので(2.1.7 識別子へ名付けてはならないワード参照)、そのような識別子も定義してはなりません。尚、上記サンプルコードの通り、リテラル演算子に対してconstexprキーワード、またはinlineキーワードを付与する事が可能です。
さて、実行結果を見てみると、それぞれの単位ごとに相互変換が行われている様子が分かります。関数fに対してサフィックスを付けずに値を渡した場合、関数fのオーバーロード解決の際に、centimetor、metor、kilometorのどれにも当てはまる事となるため曖昧となってしまい、コンパイルに失敗します。この時、例えばcentimetorのオブジェクトを渡したいのであれば、centimetor(value)というようにcentimetorのrvalueを渡してしまっても問題はありませんが、単位として見たい時に、上記のように、リテラル演算子を定義してそれを利用する事によって、値の意味を直感的に理解しやすいシーンもある事でしょう。
以上がユーザー定義リテラルの大まかな概要となりますが、ユーザー定義リテラルの機能にはいくつかの決まりがあります。順に確認していきましょう。
整数
引数で整数を受け取るリテラル演算子のシグネチャは以下のいずれかでなければなりません。
戻り値型 operator"" _サフィックス名(unsigned long long); // #1
戻り値型 operator"" _サフィックス名(const char*); // #2
template<char... >
戻り値型 operator"" サフィックス名(); // #3
まず#1と#2についてです。このように定義されたリテラル演算子を呼び出した時、引数にはその呼び出し元のサフィックス名を除いたそれぞれunsigned long long型、const char*型の値が引数に渡されます。尚、unsigned long long型の範囲を超えた値は、当然ながら扱う事ができませんが、その場合、#2か#3で扱う事が可能です。#2もしくは#3で扱った場合、渡された値は#2では\0のついた文字列として扱われます。以下では、例として#2のシグネチャを持つリテラル演算子で扱っています。
#include<iostream>
void operator"" _suffix(const char* value)
{
std::cout<<value<<std::endl;
}
int main()
{
18446744073709551616_suffix; // 筆者の環境でunsigned long long型を超える数値
}
実行結果は以下の通りです。
18446744073709551616
尚、この時#1のリテラル演算子を上記のコード中に定義し、オーバーロード解決を試みる場合、実際の値がオーバーフローするか否かに関わらず#1のリテラル演算子が呼び出されてしまうため、注意が必要です。
#3についてですが、templateという、ここまでではまだ扱っていないキーワードが出てきました。これについては、第11章 テンプレートにて詳しく説明しますので、現時点では理解しなくて構いません。
尚、bool型を引数型として受け取る事はできません。通常の関数の場合、暗黙変換が行われるため例えばunsigned long long型の値を受け取る関数に対してbool型の値を渡す事ができますが、リテラル演算子に対しては渡す事はできません。
また、先ほどもオーバーロード解決の点で注意しなければならないと述べた時に触れたように、上記三つのリテラル演算子が同時に宣言されオーバーロード解決が行われる場合、#1があれば#1が、#1が無ければ#2または#3が使用されます。尚、#2と#3を同時に宣言する場合、#1は必ず宣言しなければなりません。
また、リテラル演算子に対して以下のようにマイナス記号-を付与した場合、リテラル演算子に渡されるのはマイナス記号が適応された負数ではなく、正数のみが渡されます。
#include<iostream>
unsigned long long operator"" _suffix(unsigned long long x)
{
std::cout<<x<<std::endl;
return x;
}
int main()
{
-42_suffix;
}
実行結果は以下の通りです。
42
浮動小数点数
引数で浮動小数点数を受け取るリテラル演算子のシグネチャは以下のいずれかでなければなりません。
戻り値型 operator"" サフィックス名(long double); // #1
戻り値型 operator"" サフィックス名(const char*); // #2
template <char...>
戻り値型 operator"" サフィックス名(); // #3
それぞれの特徴やオーバーロード解決の際の優先順位は上記整数リテラルの#1、#2、#3の関係性と全く同じです。また、これらも上記整数リテラルの規則と同じように、上記三つのリテラル演算子が同時に宣言されオーバーロード解決が行われる場合、#1があれば#1が、#1が無ければ#2または#3が使用されます。尚、#2と#3を同時に宣言する場合、#1は必ず宣言しなければなりません。#3についてはまだ理解しなくとも構いません。
文字列
引数で文字列のアドレスを受け取るリテラル演算子のシグネチャは以下のいずれかでなければなりません。
戻り値型 operator"" サフィックス名(const char*,std::size_t); // #1
戻り値型 operator"" サフィックス名(const wchar_t*,std::size_t); // #2
戻り値型 operator"" サフィックス名(const char16_t*,std::size_t); // #3
戻り値型 operator"" サフィックス名(const char32_t*,std::size_t); // #4
第一引数のconst char*型へは、呼び出し元の値に付与されたサフィックス名を除いた文字列部分の先頭を指すポインタが渡され、第二引数のstd::size_tには当該文字列の長さが渡されます。
#include<iostream>
#include<cstring>
void operator"" _suffix(const char* str,std::size_t len)
{
std::cout<<str<<std::endl;
std::cout<<std::strlen(str)<<std::endl;
std::cout<<std::boolalpha<<(std::strlen(str)==len)<<std::endl;
}
int main()
{
"hoge"_suffix;
}
実行結果は以下の通りです。
hoge
4
true
数値に対するユーザー定義リテラルとは異なり、あるリテラル演算子を利用するためにはあるリテラル演算子が定義されなければならないといった規則はありません。尚上記の実行結果の通り、第二引数に渡される文字列の長さは終端文字(\0)を除いた長さの値が渡されます。
#2以降のワイド文字列などの概念については、別の項目で詳しく取り上げますので現時点で理解する必要はありませんが、そのような異なる文字単位を持つ型のリテラル演算子も定義する事ができるという事だけ理解できれば良いでしょう。
尚、文字列に対するリテラル演算子を利用して文字列リテラル同士を結合する事が可能です。その場合、定義された文字列リテラル演算子が呼び出される前に、プリプロセス時に文字列同士が単に結合され、その後呼び出される形となるため、文字列リテラル演算子の呼び出しは一度のみとなります。
#include<iostream>
void operator"" _suffix(const char* str,std::size_t)
{
std::cout<<str<<std::endl;
}
int main()
{
"hello"_suffix "world"_suffix; // サフィックスを二度用いても呼び出されるのは一度
"hello"_suffix "world"; // サフィックスを片方のみに付与してもOK
"hello" "world"_suffix; // 上記と同じ
}
実行結果は以下の通りです。
helloworld
helloworld
helloworld
上記コードのように、リテラル中にサフィックスを何度記述しても構いませんが、結合される文字列同士のサフィックスは同じでなければなりません。
文字
引数に文字の値を受け取るリテラル演算子のシグネチャは以下のいずれかでなければなりません。
戻り値型 operator"" サフィックス名(char);
戻り値型 operator"" サフィックス名(wchar_t);
戻り値型 operator"" サフィックス名(char16_t);
戻り値型 operator"" サフィックス名(char32_t);
これらのリテラル演算子は文字列に対するユーザー定義リテラルと同じように特に規定はありません。
その他の機能と制約
最後に、 リテラル演算子のサフィックスには、これまで英字を用いて定義してきましたが、ソースファイル文字として許されている場合、サフィックス名は英字に限らず利用する事が可能です。
#include<iostream>
// \u339Eは㎞のユニコード
constexpr float operator"" _\u339E(unsigned long long x)
{
return x*100.0f;
}
int main()
{
// どちらでもOK
std::cout<<1_㎞<<"m"<<std::endl;
std::cout<<1_\u339E<<"m"<<std::endl;
}
clang 4.0.0にてコンパイルし、実行結果は以下の通りです。
100m
100m
また、リテラル演算子のシグネチャとして、operator""とその後に続く_(アンダースコア)の間のスペースは必須ではありません。
// operator""と_の間にスペースを付与しなくても良い
constexpr float operator""_\u339E(unsigned long long x)
{
// ...
また、あるトークンがユーザー定義リテラルと通常のリテラルの両方に解釈可能な場合は、そのトークンは通常のリテラルとして認識されます。例えば、100E2 は、通常の浮動小数点リテラル 100.0E+2 と考える事も、整数リテラル 100 にサフィックス E2 の付いたユーザー定義整数リテラルと考えることもできますが、その場合には浮動小数点リテラルとみなされます。
#include<iostream>
// アンダースコアのないリテラル演算子の定義は違反ですので以下のようなコードを記述してはなりません。
void operator"" E2(unsigned long long)
{
std::cout<<__func__<<std::endl;
}
int main()
{
100E2; // 呼び出されない
}
その他、以下に機能と制約を列挙します。
- 全てのリテラル演算子は、Cリンケージを持ってはならないが、内部リンケージもしくは外部リンケージを持つ可能性がある
- リテラル演算子はデフォルト引数を持つ事はできない
グローバル空間への配慮
さて、ここまでユーザー定義リテラルについての機能について説明しましたが、最後に実際に利用するに当たって一つ配慮しなければならない点を挙げておきましょう。といっても、それは通常の関数の場合と同じ気遣いである事に気づくでしょう。例えば通常の関数をグローバル空間に以下のように宣言したとします。
void f();
もうこの瞬間に、グローバル名前空間にはこの関数と同じシグネチャの関数は定義する事ができなくなりました。後になって自分が、もしくは自分の書いたコードを利用する誰かが、同じシグネチャの関数fを宣言したくなったとしてもです。このように、特に他人に自分のコードをライブラリなどとして使ってもらう事を考えると、その機能を名前空間で囲む事はもはや常識です。
ですから、特に他人にコードを使ってもらう際には、独自に定義したリテラル演算子も、名前空間で囲んであげるのが、一定のマナーといったところでしょう(自分だけが使うにしても、名前空間で囲う事で識別子の衝突からまのがれる事が出来たり、関数のオーバーロード解決の際の探索範囲から除外できるなどその恩恵は大きいです)。
#include<iostream>
#include<cstring>
namespace my_awesome_lib{
struct Integer{
constexpr Integer(int x):x_(std::move(x)){}
// 内容とは無関係になるためIntegerクラス内の詳細な定義は省略...
private:
int x_;
};
namespace Integer_literal{ // リテラル演算子は名前空間で囲っておく
constexpr Integer operator"" _Int(unsigned long long x)noexcept
{
return Integer(std::move(x));
}
} // namespace Integer_literal
} // namespace my_awesome_libr
int main()
{
using namespace my_awesome_lib::Integer_literal;
my_awesome_lib::Integer x=42_Int;
}