14.1 イントロダクション
この項では、C++17 での実際のマルチスレッドプログラミングの解説の前に、スレッドとは何なのか、またそれらと関連する他の概念やそれとの違いは何なのか、それが何故必要なのか、更にシングルスレッドプログラミングでは考慮する必要のなかった競合(data races)や排他制御、アトミック性、順序関係、最適化、マルチスレッドにおけるメモリモデルなど、これらの概念を解説します。
14.1.1 用語と概念
マルチスレッドという用語、一度は聞いた事があるかもしれませんが、そもそもどのような意味なのでしょうか。プロセスやタスク、ジョブという用語は、Google などで検索するとマルチスレッドに関連して一括りにされて出てくる事もありますが、これらとの違いは一体なんでしょうか。まずはこれらの用語の意味と何故それが必要なのか、その役割を明白にしておきましょう。
並列処理
これらの単語を理解するために、まずは並列処理とは何なのか、何故必要なのかを述べておきます。例えば HDD上のファイルにアクセスするとしましょう。しかし、第12章でも述べた通り、CPUからこのような外部機器へのアクセスは一般的に低速です。このファイルアクセス中に、他の処理を済ませて置けるのであればユーザーにとっての処理時間は短くなりますね。このように、処理を1つ1つ順次実行していくのではなく、同時に実行する事を並列処理と言います。
プロセス、タスク、ジョブ
次に、プロセス、タスク、ジョブについて説明します。まず誤解を恐れずに述べてしまえば、プロセス、タスク、ジョブは、殆どの場合において同じ意味合いである事が多いです。これらは何かというと、プログラムの実行単位の事を言います。ユーザーが OS に対して、例えばエディターとウェブブラウザの起動を指示したとします。もしそれらが1つの実行ファイルから成るのであればそれはまた話は別になってしまいますがそうではなく、それぞれ全く別の実行ファイルから実行されているのであれば、メモリー上に配備されたそれぞれの実行部分がプログラムの実行単位であると言えます。
さて、これらの微妙な意味合いの違いを考えて見ましょう。まずは、プロセスとタスクについて考えていきます。プロセスは、前述した通りプログラムの実行単位を示す用語ですが、それと同時にOS 側の視点から見た用語であるとされる事が多いようです。例えば Win32 API という、Microsoft 社 による Windows OS の各機能にアクセスするためのインタフェースセットには、タスクという用語が一切使われていません。例えば、プログラムの起動のための CreateProcess.aspx) という関数が同 API には備わっています。それと比較して、タスクは、プロセスという用語の対となるように、ユーザー側の視点から見た用語であるとされるようです。同 OS の画面下に表示されるプログラムが並ぶバーは、タスクバーと呼ばれていますし、他指定した日時にプログラムを起動するタスクスケジューラという同 OS の付属ツールもタスクという用語が使われています。このように Windows においてタスクという用語は単なる作業という意味で使われているように受け取れます。以上有名な企業による用語の使用例を述べましたが、この通り、明確な定義がないため、その意味合いは文脈から判断する必要があるでしょう。しかしそれはつまりその程度の違いしか両者にはないという事です。
次にジョブとは何でしょうか。ジョブという用語も実は前述した二つの用語との明確な差異が定義されているわけではありません。ただ傾向として、これもユーザー側の視点から見た用語であると言われる他、複数のプロセスをグループとして扱う場合に、同 API では Job Object を作り、これにプロセスを登録してグループ化する事で、ジョブの状態やジョブに属する全てのプロセスの終了などを可能にします。
中々この三つの用語の違いがはっきりしないのであまり気持ちよくないかもしれませんが、元々定義が明確となっていないため、三つの違いに関しては雰囲気だけ理解できれば良いでしょう。また、この三つがプログラムの実行単位を示す用語である事が理解できれば良いでしょう。本章では、以降、プロセス、タスク、ジョブをまとめてプロセスと呼称します。
最後に、プロセスの特徴について押さえておきましょう。プロセスは、前述した関数などを用いてプロセスを起動する事ができます。このように、プロセスから起動されたプロセスは子プロセスと言い、起動した側のプロセスを親プロセスと言います。プロセスには、このような親子関係がありますが、それぞれのプロセスごとに別のメモリ領域を利用します。また、命令の実行処理タイミングも異なります。
Windows などのマルチタスク(プロセス) OS は、複数のアプリケーションを同時に実行できますが、それは OS によるサポートがあっての事です。一つのCPU(シングルコア)しかないコンピュータでは、ある一瞬では一つの処理しか実行できません。
これを OS によるマルチプロセス処理で解決します。異なるアプリケーション(実行単位、つまりプロセス)が複数の動作を同時に行なっているように見せるために、各処理プロセスを数十ミリ秒といった短い時間で素早く切り替えて、タスク間で一つの CPU を使いまわします。これをマルチプロセス(マルチタスク)またマルチプロセス処理(マルチタスク処理)と言います。また、このように処理の流れを一時停止して別の処理に切り替えて実行を行なったり、再開する事をプリエンプションと言い、またその過程をコンテキストスイッチと言います。コンテキストスイッチ処理は、オーバーヘッドがあり、処理時間の観点からしても払わなければならないコストとなる事を覚えておきましょう(このようなプロセス切り替えで発生するオーバーヘッドについては後述しています)。
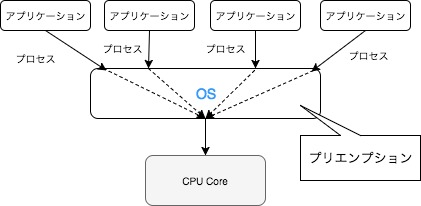
尚複数のCPU(マルチコア)を持つコンピューターでは、複数のプロセスを文字通り同時に実行します。以下の図の場合、事実上上記のシングルコアシステムと比較して、半分の量のコンテキストスイッチ切り替えとなります。
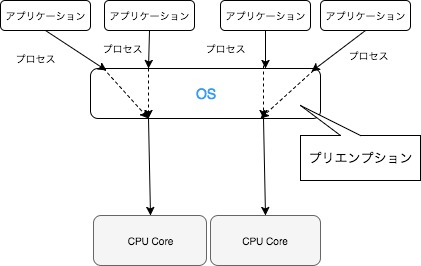
このようなプリエンプションを行う OS をプリエンプティブなOSと言います。またそうでない OS をノンプリエンプティブなOSと言います。ノンプリエンプティブなOSでは、実行プロセスの切り替え管理を実行プロセス自身に任せますから、そのプロセスが自発的に CPU を解放しなければなりません。よって、解放されるまでの間、1つのプロセス実行中は、他のプロセスの実行が制限される事となります。プリエンプティブなOS では前述した通り、スケジューラが各プロセスをある短い時間ずつ実行します。この短い時間をタイムスライスと言います。プロセスがスケジューラの設定したタイムスライスの時間内に CPU を明け渡さなかった場合、OS によるタイマ割り込み(割り込みについては後述しています。)が発生し、OSが別のプロセスを実行させるようにスケジューリングを行い、コンテキストスイッチが発生します。
また、複数のプロセス間でデータをやりとりする事もできます。これを、プロセス間通信と言います。
尚、マルチプロセスとは反対にに一つのプロセスしか実行できない方式をシングルプロセス(シングルタスク)またシングルプロセス処理(シングルプロセス処理)と言います。
プロセス切り替えのオーバーヘッドと割り込み
プロセス切り替えにはオーバーヘッドがあるという事を述べました。そして割り込みという用語が出てきました。これらについて少し掘り下げておきましょう(しかしあまりにも詳しく触れるとカーネルについての参考書となってしまうため、ここでは少ししか掘り下げません。)。
プロセス切り替えには、その切り替え自体オーバーヘッドがある他に Translation Lookaside Buffer(TLB) のミス率の上昇などのコストがあります。TLB は仮想アドレスから物理アドレスへの変換の高速化を測る仕組みです。今日の仮想記憶をサポートするマイクロプロセッサの殆どが、仮想空間と物理空間のマッピングに TLB を利用しています。TLB は連想配列に似たデータ構造である連想メモリで実装されており、CPU がメモリ空間にアクセスする際、検索キーとして仮想アドレスを利用して TLB 上にそのアドレスに対応したエントリがあれば、検索結果として対応する物理アドレスが返るようになっています。これをTLBヒットと言います。要求したアドレスがない事をTLBミスと言い、TLB のミス率上昇はこれが偶発する確率を上昇させてしまう事を言います。TLBミスである場合、ページテーブル(仮想アドレスと物理アドレスのマッピングを格納したテーブル)を線形探索しなければならなくなってしまいます。この探索を、ページウォークと言います。ページウォークは複数個所のメモリ内容から物理アドレスを計算しなければなりませんので、時間がかかってしまうのです。尚、一度 TLBミスからページウォークによって判明した物理アドレスは、その仮想アドレスと物理アドレスのマッピングが TLB に追加される事となっていますから、アドレスの変化がなければ二度目では必ず TLBヒットします。しかし、コンテキストスイッチを行うとその際に仮想空間の切り替えに伴って TLB エントリの一部が不正となってしまうため、中々無視できるコストではありませんから、この点をよく考える必要があります。
次に割り込みについてです。割り込みとは、コンピュータがその周辺機器から受け取る要求の一種です。主に、実行中の処理を中断して、強制的に指定された処理を実行させる事を言います。要求には、ハードウェアによるものとソフトウェアによるものがあります。ハードウェア割り込みは、コンピュータの周辺機器などのハードウェアから発生させる割り込みで、ある装置を経由して CPU に信号を送られ OS が実行中の処理を中断して機器の制御に必要な処理を実行します。この装置を割り込みコントローラと言います。次に、ソフトウェア割り込みは、実行中のプログラムが発生させる割り込みの事を言います。これは、例外的な事象が発生した事を OS に伝えて、処理を中断し適切な対応を OS に迫ります。Segmentation fault などがこれに当たります。
スレッド
次に、スレッドとは何なのかについて説明します。尚、この時点では、C++ 言語における厳密なスレッドの定義については触れず、言語仕様とは切り離してより一般的なスレッドとしての概念について述べます。厳密な定義については、当章後半にあたる 14.1.6 C++ のマルチスレッドにおけるメモリモデル にて説明します。
さてスレッドとは、前述したプロセス、タスク、ジョブとは、意味としては明確に異なります。スレッドとは CPU利用の単位を意味しています。シングルスレッド、マルチスレッドといった用語を聞いたことがあるかもしれませんが、それぞれある処理を単一のスレッドのみを用いて動作させる事をシングルスレッド、対して複数のスレッドが同時に動作することをマルチスレッドと言います。1つのプロセス(単一の実行単位)は1つ以上のスレッドを必ず持っています。つまりスレッドは、プロセスまたはスレッドそのものから生成されるという事です。
マルチプロセス処理とは、根本にある考え方は同じですが、単位が異なります。
マルチスレッドは、前述した通り1つのプロセスが1つ以上持つ事ができますから、1つのプロセスが持つ特定の操作のそれぞれを個々のスレッドに分割するといった事ができます。複数のプロセス間でデータをやりとりできるように、プロセス上に成る複数のスレッド間でもデータをやりとりする事ができます。ここまでは、その機能としてはプロセスと変わりません。唯一の違いはOS全体で管理されるプロセス単位であるか、OS全体で管理されるプロセスのさらに内部で管理されるスレッド単位であるかといった点です。何故プロセス単位ではなく、プロセスの内部で複数のスレッドを実行するのでしょうか。
大きな理由の一つとしては、前述したプロセスの切り替え(プリエンプション/コンテキストスイッチ)動作コストを避けるためです。TLB ミスについて懸念する必要もありません。かつてスレッドはライトウェイトプロセスとも呼ばれていました。これはひと昔前の UNIX に由来しています。かつての UNIX にはプロセスしかなく、並列処理を行うためには一つのプロセスから別のプロセスを作っていました。しかしここまで述べてきた通りコストがかかるため、プロセスよいも高速な手段で並列処理を行うための方法としてスレッドが導入されたという歴史があります。このようにプロセスのように独立したメモリ空間が不必要であったり、共有のメモリを利用しながら複数の処理を行なった方が楽であったりする場合、マルチスレッドはとても良い選択肢の1つです。プロセスの機能から必要な部分のみを利用したものがスレッドであるといったようなイメージがつけば良いでしょう。
さて、ここまででプロセスとスレッドについて見てきましたが、ここでそれぞれのメリットとデメリットをまとめておきましょう。
マルチスレッドのメリットとデメリット
メリット
- メモリ使用率が低く、プロセス切り替えのオーバーヘッドがない
- プロセスよりも少ない時間で生成できる
デメリット
- 1つのスレッドがクラッシュするとそのプロセス全体に影響を及ぼす
- マルチスレッドプログラミング特有の排他制御や順序関係(後で説明しています)について適切に対処しなければならないため、そのためのスキルが必要
マルチプロセスのメリットとデメリット
メリット
- 実行単位がそれぞれで分離しているため、1つのプロセスがクラッシュしても全体に影響はない、または起きにくい
- シングルスレッドでのプログラミングが可能
デメリット
- プロセス切り替えのコストがかかる
- プロセスの作成にコストがかかる
14.1.2 データ競合(data racing)
さて、ここまででプロセスやスレッドについて説明してきました。本章ではC++17 でのマルチスレッドについて取り上げていますが、言語に関わらず、マルチスレッドプログラミングではシングルスレッドプログラミングで特別懸念しなくても良かった細部が根本的な問題を生じるようになります。その1つとしてまずはデータ競合(data races)について見ていきます。C++ においてデータ競合とは、以下の条件を満たす場合に発生します。
- 並列で動いている複数のスレッドの内の1つ以上が
- 同じ瞬間に(実際に同じ瞬間となるかは不定)同じメモリ位置にある排他制御のされていないまたはアトミックでないデータへのアクセスにおいて
- 変更を加える操作がある時
さらに、もし C++ でデータ競合のあるコードを書いた場合、そのコードは未定義の動作を引き起こします。つまり、1つでもデータ競合を含むマルチスレッドプログラムの動作結果について C++ 言語仕様としてはは全く保証しません。全く保証しないので、意図した通りに動く事もあるでしょう。しかし意図した通りに動かない事もあるでしょう。マルチスレッドプログラミングにおいて、データ競合が起きないプログラムを書く事は、そのプログラムの信頼性に直結する、とても重要な事なのです。尚、このような C++ における規則はメモリモデルとして厳密に定義されています(メモリモデルについては、一通り知識を得てからの方が理解に容易いだろうと思われるため、当章の 14.1.6 にて再度取り上げています)。
ここまででは、まだ C++17 でのマルチスレッドプログラミングにおける実際のライブラリやその具体的な使用方法について述べていません。それは、コードに起こす前にマルチスレッドプログラミングにおける注意点を理解しなければ未定義の動作によってこの世の終わりが訪れてしまうかもしれないからというのもありますが、まずはマルチスレッドと切り離して C++ でのシングルスレッドコードについて見て見ましょう。
int main()
{
unsigned char x = 'a';
unsigned char a = x;
unsigned char b = x;
}
これはシングルスレッドコードです。そうです、今まで書いてきたコードは、シングルスレッドのコードなのでした。1つの実行単位はプロセスであり、スレッドはプロセスまたはスレッドから生成されます。コードでは、xからaとbそれぞれが値を読み取っています。この場合、以下のイメージ図のようにそもそも1つの領域に対して同時にアクセスされる事すらまずないですから、競合は起こりえません。つまり、シングルスレッドコードでは競合は起きません(現時点では深くは触れていませんが、以下の図は最適化におけるデータへのアクセス順序の変動について考慮していません。あくまでイメージです。これについては後に重要なファクターとなります。)。

次にマルチスレッドの動作について考えて見ましょう。前述した通りまだ C++17 におけるマルチスレッドプログラミングの具体的な方法について述べていませんから、まずは擬似コードと図から考察していきます。
int main()
{
unsigned char x = 'a';
auto スレッド処理内容1 = [&x]{ [[maybe_unused]] unsigned char a = x; };
auto スレッド処理内容2 = [&x]{ [[maybe_unused]] unsigned char b = x; };
スレッド スレッド1 = スレッドの処理内容1;
スレッド スレッド2 = スレッドの処理内容2;
スレッド1.処理待ち();
スレッド2.処理待ち();
}
各スレッドがそれぞれ同じメモリ領域に位置するデータを読み取っています。この時、xに対するアクセスは完全に同じ瞬間かもしれませんし、若干そうでないかもしれません(下図では同じ瞬間にそれぞれのスレッドがxにアクセスしている例です)。
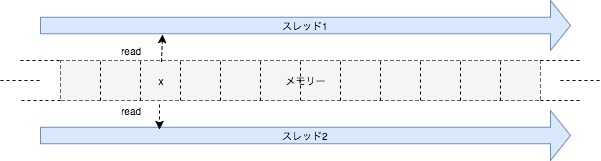
さてマルチスレッド処理となりましたのでデータ競合問題について考えなければなりません。データ競合は前述した通り並列で動いている複数のスレッドの内1つでも同じメモリ位置にある排他制御がされていないデータを変更する操作を行うと発生してしまいます。上記の処理の場合、複数のスレッドが同じメモリ位置にアクセスはしていますが、それらの両処理は変更操作ではないのでデータ競合は起こりません。次の例を見て見ましょう。
int main()
{
unsigned char x = 'a';
auto スレッド処理内容1 = [&x]{ x = 'b'; };
auto スレッド処理内容2 = [&y]{ x = 'c'; };
スレッド スレッド1 = スレッドの処理内容1;
スレッド スレッド2 = スレッドの処理内容2;
スレッド1.処理待ち();
スレッド2.処理待ち();
}
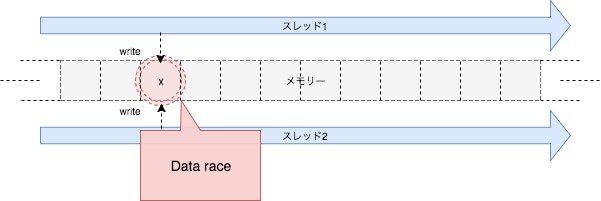
この例は、並列で動いている複数のスレッドが同じメモリ位置にあるデータを変更していますから、データ競合、つまり未定義動作を引き起こす擬似コードとなってしまいました。続いて次の例も見て見ましょう。
int main()
{
unsigned char x = 'a';
auto スレッド処理内容1 = [&x]{ x = 'b'; };
auto スレッド処理内容2 = [&y]{ [[maybe_unused]] unsigned char a = x; };
スレッド スレッド1 = スレッドの処理内容1;
スレッド スレッド2 = スレッドの処理内容2;
スレッド1.処理待ち();
スレッド2.処理待ち();
}
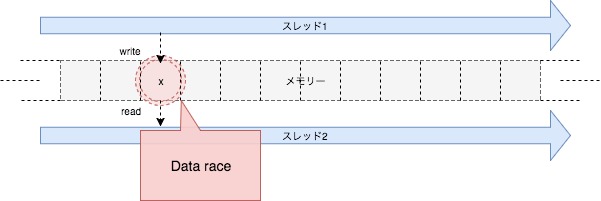
スレッド1は書き込み、つまり変更操作ですが、スレッド2は読み込み操作です。しかしこの場合でも、データ競合となってしまいます。それもそのはず、例えば片方のスレッドの書き込みが完了していない間に読み込んでしまうかもしれませんし、たまたま書き込み済みのデータを取得できるかもしれませんし、たまたま書き込みがまだのデータを取得できるかもしれません。またスレッド2がデータを読み込み初めて完了するまでの間に、スレッド1がデータを変更してしまうかもしれません。このようなものを保証する手立ては考えられません。よって同じく未定義動作となります。
データ競合とは何なのか、そして実際に起こりうるシーンはどのようなものなのか見てきましたが、ここまで見て考えてみると、マルチスレッドというものはあまりにも不便に思えるかもしれません。複数のスレッドがアクセスしうる同一のデータへの変更操作が加わった途端に、データ競合が発生してしまうだなんて、じゃあマルチスレッドプログラミングでは変更操作を全くする事ができないのだろうか?と思うかもしれません。しかし安心してください。そのために排他制御、アトミック操作と言われるものがあります。
14.1.3 排他制御とアトミック
データ競合が起きてしまう条件を振り返って見ましょう。
- 並列で動いている複数のスレッドの内の1つ以上が
- 同じ瞬間に(実際に同じ瞬間となるかは不定)同じメモリ位置にある排他制御のされていない、またはアトミックでないデータへのアクセスにおいて
- 変更を加える操作がある時
排他制御のされていない...データへのアクセスにおいてとあります。つまり、排他制御というものがあれば変更を加える操作を行なってもデータ競合とはならないのでしょうか?正に、その通りなのです。排他制御とはどのようなものなのでしょうか。といっても考え方はとてもシンプルです。
未定義動作となってしまう原因の根本にあるのは、変更操作が開始してからにその操作が完了するまでの間に、他のスレッドがそのデータを読み取ってしまうか、読み込みが開始してからそのが完了するまでの間にデータが変更されてしまう事です。ならば、変更操作中、または読み込み中にそのデータに対するアクセスを禁止してしまって、変更操作または読み込みが完了してからアクセスさせれば良いわけです。それが、排他制御と言われるものです。このようなアクセス制限を課す動作をロックする、ロックを取得すると言い、アクセス制限を解除する事をアンロック、ロック解放、ロック解除などと言います。以下に先ほどの擬似コードに対して排他制御を加えてみます。
int main()
{
unsigned char x = 'a';
auto スレッド処理内容1 = [&x]{ ロック; x = 'b'; アンロック;};
auto スレッド処理内容2 = [&y]{ ロック; [[maybe_unused]] unsigned char a = x; アンロック;};
スレッド スレッド1 = スレッドの処理内容1;
スレッド スレッド2 = スレッドの処理内容2;
スレッド1.処理待ち();
スレッド2.処理待ち();
}
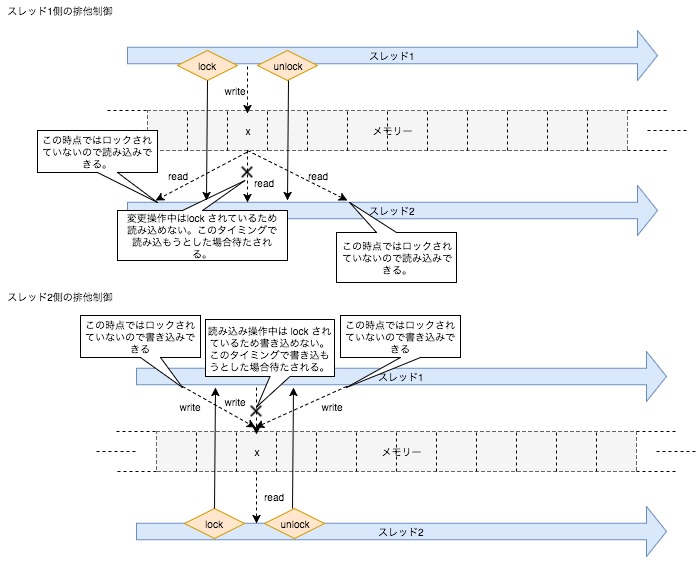
このように、ロックを取得する事でアンロックするまでの間、他のスレッド処理の介入を防ぐ事ができます。排他制御によって、スレッド2にてxから取り出した値、つまりaで取得する値は'a'または、'b'である事が保証されるのです。しかしここでさらに問題が浮上してきました。それは、スレッド同士の順序関係は全く予測できないという事です。ここでアトミックについて見ていきます。まず、アトミックな型をアトミック型と言います。アトミック型はアトミックな操作(不可分操作)を行う型であり、アトミックな操作とはデータへの不可分な読み込みや書き込み、及び読み書きを同時に行う操作を意味します。アトミック操作は、主に以下の2つの条件を満たしたものを言います。
- 全操作が完了するまで、他のスレッドまたはプロセスなどはその途中の状態を観測できず
- 一部操作が失敗した場合、組み合わせ全体が失敗し、その状態は不可分操作を行う前の状態に戻る
これらを満たすアトミック型の変数をアトミック変数と言います。C++ では、このアトミック性を各操作間の順序関係を保証する事で表現します(実は実行順序/評価順序に関わる懸念は、マルチスレッドプログラミング特定の問題ではありません。もしかなり余裕がある場合は、16.5 評価の順序をご覧ください。ただしかなり余裕がなければ混乱させてしまう可能性もあるため、現時点で読まなければならないという事は全くありません。)。ここで一旦言葉の定義を踏まえて用語を押さえておきます。まずなんらかの操作、つまり値の計算や値の変更、変化の事をアクションと呼びます。次に A というアクションを内包するスレッド X と、 B というアクションを内包するスレッド Y があり、スレッド Y 中のアクション B が始まる前に必ず スレッド X 中のアクション A が完了している事を、A happens before Bと言います。このようにhappens beforeは、C++ 言語では一般的にマルチスレッド間におけるアクションの順序関係を示します。
以降では、この実行順序関係に関わる問題について掘り下げていきます。マルチスレッドにおける実行順序に関する問題は、最適化と深く関わりがあり、これについて一旦理解する必要がありますので、まずは最適化の規則について大まかに説明します。
14.1.4 最適化とは
最適化はどのような条件下で行えるのでしょうか。この項では、一旦マルチスレッド特有の話から離れてシングルスレッドでも共通の話題として取り上げます。
まず、1.2 C++17とはで述べた通り、C++ 言語は国際標準の言語規格が制定されています。プログラマーはその規格に基づいてコードを書きます。それに対して各ベンダー、所謂コンパイラ作者は、その規格に準じてコンパイラを開発します。こうする事で、言語として最も重要な要素の1つである共通認識を統一し、より一般的な議論、開発が出来るようになります。規格に準拠したコンパイラを使う事で、そのチェックを受けたコードの規格準拠度は確実なものとなりますから(未定義動作も含めて)、何か問題が発生した場合、その特定を容易にする事ができるでしょう。各ベンダーは規格に基づいて(そうであって欲しい)おのおのの開発を進行しますが、一つだけ(実装依存などを除いて)ベンダーごとに全くその動作が異なっても標準規格準拠 C++ であると認めているものがあります。それが、最適化です。ある一定のルールに基づく場合、コンパイラごとに異なる最適化の結果を実行形式バイナリとして出力する事が許されています。厳密に言えば、ある一定のルールに基づくコードの変換を C++ 言語は許可しています。
そのある一定のルールは、プログラムのobservable behavior(観測可能な振る舞い)を変更しない事です。observable behavior とは、プログラムを実行した際にユーザーが観測する事ができる挙動を言います。よって例えばメモリのどの位置にどのようにアドレッシングされたかなどはユーザーの観測対象ではありません。勿論観測する事が可能な環境は有りえますが、この場合 C++17 としてはそれをユーザーによる観測対象としません。つまり、次の項目は最適化(プログラムの変換)はされず、保守されます。
volatileオブジェクトに対するアクセス(読み書きに関わらず)はそれらが発生する式のセマンティックスに従って厳密に行われる。特に同一スレッド上の他のvolatileオブジェクトへのアクセスは並び替える事はできない。- プログラムの終了時にファイルに対して書き込まれたデータは、まるでコーディング時のプログラムが実行されたように書き込まれるデータと同じでなければならない。
- インタラクティブデバイスの入出力の挙動において、入力の前に入力を促すための出力を必ず表示しなければならない。
#pragma STDC FENV_ACCESSが ON に設定されている場合、浮動小数点環境への変更(浮動小数点例外及び丸めモード)は、浮動小数点演算子及び関数呼び出しによって- キャストと代入以外の浮動小数点式の結果は、式の型と異なる浮動小数点型の範囲と生後を持つ事がある (1)。
- (1) に関わらず、
#pragma STDC FP_CONTRACTが OFF に設定されている場合を除いて浮動小数点式の中間結果は、無限な範囲と精度を持っているかのように計算される。
これらを、observable behavior と言い、observable behavior を変更しない事をas-if ルールと言います。
尚、定義されない振る舞い(undefined behavior)を持つプログラム、例えば範囲外の配列へのアクセス、constオブジェクトの変更、評価順序の違反などは as-if ルールも守られません。よって、異なる最適化設定で再コンパイルなどした際は観測可能な動作を変更する事があります(undefined behavior に関して深堀する事は無意味ですからこれに関してはあまり触れません)。
また、new演算子を使った文では as-if ルールからのもう一つの例外があります。コンパイラは、ユーザーから、ユーザー定義のアロケート関数の置換が提供され、観測可能な副作用があっても(副作用については16.5 評価の順序で解説しています。)置換可能なアロケート関数への呼び出しを除去する事ができます。
14.1.5 リオーダー、メモリバリア
as-if ルールと言われる最適化規則を述べたところで、次にリオーダーについて説明します。リオーダーとはコンパイラ、またはプロセッサによる最適化です。プログラムの実行速度向上を測るため、実行順序を入れ替える最適手法の一つです。実行順序の入れ替えは、シングルスレッド上で前述した as-if ルールの基、実行結果が歪曲されない場合許可され(シングルスレッド次元における最適化に関する項目 strict alias rule については16.1 strict alias ruleにて取り上げています。)、主にコンパイル時、つまり機械語プログラムへの変換の間と、実行時、つまり CPU が機械語を実行する際に行われます。それぞれ、コンパイル時では命令の配置順序を入れ替え、実行時ではメモリに対するアクセス順序を入れ替える事でリオーダーが実現されます。例えば以下のように、シングルスレッド上で実行結果が変わってしまうような場合、コンパイル時、実行時ともにリオーダーはされません。
x = 42; // (1)
y = x; // (2)
(1) と (2) を入れ替えてしまうと、yに代入される値が変わってしまうため、このような場合はリオーダーされません。しかし、(2) の代入を以下のように最適化する事は可能です。
y = 1;
以下のような場合、リオーダーされる可能性があります。
x = 42; // (1)
y = 42; // (2)
a = x; // (3)
b = y; // (4)
この場合、(1) と (2) 、(3) と (4) をそれぞれ入れ替えても実行結果は変わりません。しかし、冒頭で太字で述べているように、シングルスレッド上で実行結果が変わらない場合にリオーダーが許可されるのでマルチスレッド上ではその順序付けは全く保証されないのです。つまり、その実行した結果が変わってしまうとしても、コンパイル時もしくは実行時にリオーダーされてしまうかもしれません。以下擬似コードでその例を再度示します。
int main()
{
int x = 0,y = 0;
auto スレッド処理内容1 = [&x]{ ロック; x = 42; y = 42; アンロック;};
auto スレッド処理内容2 = [&y]{ ロック; [[maybe_unused]] int a = x; [[maybe_unused]] int b = y; アンロック;};
スレッド スレッド1 = スレッドの処理内容1;
スレッド スレッド2 = スレッドの処理内容2;
スレッド1.処理待ち();
スレッド2.処理待ち();
}
この場合、実行結果は以下の内のどれかとなります。
a == 0 and b == 0a == 42 and b == 0a == 0 and b == 42a == 42 and b == 42
シングルスレッドでは、確実にa == 42 and b == 42となりましたが、複数のスレッドにおける順序付けは全くされていないので上記のどのパターンでもあり得てしまうのです。これに順序付け、規則を適用するのが、メモリバリアまたはメモリフェンスと言われるものです。C++ においてメモリバリアはいくつか種類があり、それぞれバリアのレベルが異なります。整合性/順序関係を明示したい該当箇所に対して各メモリバリアを指示する事で、実行まで確実にその制限が課せられるようになっています。前述した通り、C++ におけるアトミック型は正に各操作間の順序関係を保証する型ですから、これに対して適切なメモリバリアを設定する事で実現します。さて、実際にどのようなメモリバリアが C++17 に用意されているのか、それについては次章で取り上げます。
最後に、ここまでの総括をしておきましょう。
- C++ においてデータ競合(data races)は、複数のスレッドが同箇所のメモリに対して同時に読み/書きを行う事で発生する。
- C++ においてデータ競合(data races)が発生すると、未定義動作を引き起こす。
- データ競合を防ぐためには排他制御を行い、同じ瞬間のアクセス/操作を防止する。
- データ競合を防ぐためにはアトミック型を使う。
- アトミック型にメモリフェンスを設定する事で、設定された制限を基にした順序付けを複数のスレッドを跨って適用する事ができる。
14.1.6 C++ のマルチスレッドにおけるメモリモデル
ここまでのスレッドとは何かなどの根本的な定義は、 C++ 特有の厳密な定義ではなく、言語とは無関係に一般的に行われる認識を踏まえた解釈の説明のみでした。C++ のマルチスレッドにおけるメモリモデルは、このような基本的な概念を厳密に定義します。そもそも、メモリモデルという用語は、C++ の抽象マシンのためのメモリリソース域に対するセマンティックスを定義するものです。つまり、マルチスレッドにおける C++ メモリモデルとは、主にスレッド、データ競合、メモリの順序、またそれに基づいた標準ライブラリの振る舞い、仕様を定めるものといっても差し支えないでしょう。これについて、さらに深く述べていきますが、その殆どは一般的な認識/解釈と、そこまでの相違を感じる事もないでしょう。しかし、この項目はとても形式的な内容となり、プログラマー側の立場で考慮する必要があるかと言われるとあまりそうであるとも思えないので、特別深く理解する必要はないかもしれません。理解する必要があるかの判断は読者に任せる事とします。
- 実行スレッドとは、トップレベル関数(後に説明する標準スレッドライブラリである
std::thread、std::asyncやまたは他の手段)の呼び出しで開始するプログラムないでの制御の流れを言います。 - 全ての実行スレッドは、プログラム内の任意のオブジェクトに対して潜在的にアクセスする事ができます。そのスレッドを生み出した親スレッドに対するデータへアクセスする事ができる事は当然の事ですが、更に例え自動変数及びスレッドローカル記憶域にあるオブジェクトに対しても、ポインタまたは参照によって別のスレッドによって引き続きアクセスする事ができます。よってこれを潜在的にアクセスする事ができると言います。
- 実行の異なるスレッドは、干渉及び同期の要件なしで異なるメモリ位置に対して同時にアクセス(読み込み及び変更)する事ができます。
- データ競合は未定義の動作を引き起こします。データ競合の定義は、前述した通りです。
- スレッドがあるメモリ位置から値を読み取ると、初期値、その同一スレッドで書き込まれた値、または別のスレッドに書き込まれた値が読み取られる事があります。各スレッドに対して任意の順序を適用するためには、メモリバリアを利用します。
- 標準ライブラリ関数でブロックされていないスレッドが1つだけ lock-free のアトミック関数を実行すると、その実行は完了することが保証されます。これをObstruction-Freedomと言います(Obstruction-Freedom は C++ 特有の用語ではありません)。
- lock-free アルゴリズムとは、複数スレッド間で共有されるデータにロックを掛けて保護するアルゴリズムとは異なり、複数のスレッドが同時並行的にそのデータを壊さずい読み書きする事を可能とするアルゴリズムを言います。つまり、スレッドがロックしない事を意味します。wait-freeと呼称される事もあります。
- Obstruction-Freedom は最も弱い自然なノンブロッキングの保証を言います。つまり、任意の時点でステップ数が有限である単独で実行される単一のスレッドがその動作を完了する場合、そのアルゴリズムの実行は必ず完了されます。全てのlock-free アルゴリズムは Obstruction-Freedom です。
- Obstruction-Freedom は、部分的に完了した操作を中止して、変更を元に戻す事だけを要求します。
- 1つまたは複数の lock-free アトミック関数が同時に実行され流場合、少なくとも1つが完了する事が保証されます。
- 有効な C++ プログラムは、全てのスレッドは最終的に次のいずれかを行います。
- 終了する
- I/O ライブラリ関数を呼び出す
volatileglvalue を介してアクセスを実行する- アトミック操作または同期操作を実行する
- C++ は観測可能な振る舞いを実行する事なく、実行スレッドを永久に実行する事はありません。観測可能な動作を持たない全てのループが削除される可能性があります。
- 他のスレッドが進行中であるかどうかに関わらず、終了していない限り一定の時間内にスレッドは進行する事を、concurrent forward progress guaranteeと言います。標準規格は処理系に対して標準スレッドライブラリである
std::threadが concurrent forward progress guarantee である事を推奨しますが、要件ではありません。 - concurrent forward progress guarantee に対して parallel forward progress guarantee は、実行ステップ(I/O、
volatile、アトミック、または同期)をまだ実行していないスレッドが最終的に進行する事を保証する必要はありません。 - また、weakly parallel forward progress は他のスレッドが進行しているかどうかにかかわらず、最終的な進行を保証しません。
14.1.7 volatile の意味
ところで、C++ にはvolatileというキーワードがあります。今まで特別このキーワードについて触れてきませんでしたが、「xx でない」という事を強く学ぶ事のできる良い機会ですからここで触れておきましょう。ただ、マルチスレッドと題した章で C++ のvolatileについて触れると勘違いされる可能性があるのでまず初めに述べておきますが、C++ におけるvolatileキーワードの効果は、複数のスレッド間を跨いで発揮されるものではありません。他言語で、volatileというキーワードがマルチスレッドプログラミングにおける重要な要素(アトミック性やメモリバリア効果など)を備えたキーワードとして定義されている事があるため勘違いされやすいですが、C++ においては全くそのような意味合いのキーワードではありません。では、volatileキーワードとは具体的にどのようなものなのか見ていきます。
まず、volatileキーワードは修飾子であり、constキーワードと同じ部類になります。volatileなintの変数は以下のように宣言します。
volatile int x;
尚、volatileでない glvalue を通じてvolatileなオブジェクトを参照しようとすると、未定義の動作を引き起こします。volatileキーワードの最たる必要性は、14.1.4 で述べた observable behavior として扱われる機能です。つまり、単一スレッド内における最適化、リオーダーを防止する事ができるのです。ですからvolatile修飾して、複数のスレッド間で共有された場合、そのデータへの(C++ におけるメモリバリアなどの効果も含めた)アトミック性はありません。